在腾讯文档快速发展的初期阶段,几大品类都是参考开源项目,由几个团队分别进行快速迭代开发。这种开发模式支撑腾讯文档度过了艰难的初创阶段,在快速抢占市场的时候,借助开源项目来快速开发大概率是正确且唯一的选择。 这些开源项目彼此之间的技术栈和实现思路都是完全不同的,到现在腾讯文档发展到近10个品类,仓库里存在数百万行前端代码,虽然各品类的代码经过了几轮重构,已经全部转为自研代码。但一开始技术栈和底层基础设施的不一致,导致我们在重构过程中的节奏难以保持一致,仍然给现在留下了大量的技术债务。
背景
在腾讯文档快速发展的初期阶段,几大品类都是参考开源项目,由几个团队分别进行快速迭代开发。这种开发模式支撑腾讯文档度过了艰难的初创阶段,在快速抢占市场的时候,借助开源项目来快速开发大概率是正确且唯一的选择。
这些开源项目彼此之间的技术栈和实现思路都是完全不同的,到现在腾讯文档发展到近10个品类,仓库里存在数百万行前端代码,虽然各品类的代码经过了几轮重构,已经全部转为自研代码。但一开始技术栈和底层基础设施的不一致,导致我们在重构过程中的节奏难以保持一致,仍然给现在留下了大量的技术债务。
在业务走过存亡阶段之后,我们需要回过头来思考这些技术债务,对业务以后的发展会造成哪些影响:
- 各品类的技术栈和底层基础设施都不一致,导致服务&模块&组件的可复用性不高,同一个需求经常需要在各个品类中重复开发,产品迭代效率受到影响
- 因为技术栈和基础服务不统一,团队许多宝贵的经验无法在各品类中顺利共享,比如网络层、离线层这些难点模块,各团队曾经反复踩坑
- 维护成本随着品类数量、代码行数的增加翻倍,且没有办法收敛。
目标
我们的目标希望各个品类能构建在具有一致性的平台和架构上,各品类能尽量多的复用基础服务和其他服务,付出一次需求开发或者维护的成本,希望能给所有品类同时带来收益。最终实现前端业务级大仓。
问题
前段时间刚好在码客上看到这样一个问题:
在某个角度看来,腾讯文档业务其实和码客上这位同学的业务,要解决的是同一类问题。虽然腾讯文档面临的实际问题域还要大一些。
我们需要面对的问题,其实是如何解决一致性和个性化矛盾之间的问题。腾讯文档当前有7个品类,3个终端,数百万行前端代码。
既然我们想让这些品类尽量能保持一致性,那么就必然也要去解决它们之间的细节分歧差异。复制粘贴和if、else肯定是不行的,目前这些品类和终端的数量,已经不允许我们通过if,else,复制粘贴,或者适配层等方式去处理分歧差异了,而且在tob多租户的场景下,每个租户可能都会有自己的个性化诉求,我们可以看成,以后将遇到成百上千个品类,和成百上千个终端的场景,if,else和复制粘贴都明显是条绝路。
思路
要明白的是,各个品类&租户之间的分歧从来不会消失,分歧是和产品需求一一对应的,表格和文档,文档和ppt,它们的产品形态由多少不同,代码中就应该存在多少分歧。
分歧虽然不会消失,但我们可以尝试将这些分歧挪到更容易修改的位置,用更简单的方式来表达和维护。当分歧发生时,我们为了解决分歧而付出的代价,至少比堆砌if、else、或者复制粘要来的更小一些。
可以尝试按下面几步来解决问题:
- 分别寻找各个品类&租户之间的共同抽象特性和细节分歧
- 将这些共同抽象特性封装起来,放置在系统的高层位置
- 将细节分歧提取到系统低层,用各种更加简单的方式来表达和维护
- 让低层细节分歧去依赖高层抽象共性,遵循单向依赖原则,保证在处理细节分歧时,不会
影响到高层抽象共性
分歧在哪里
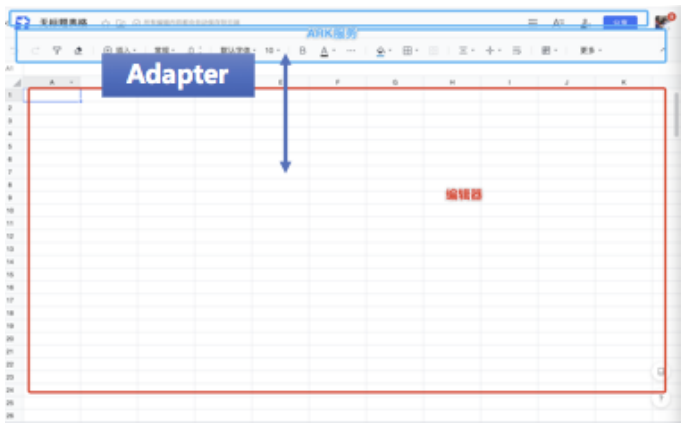
先拿sheet、doc、slide、流程图4个品类来进行观察,很明显,它们最大的分歧是编辑区(红色方框)位置几乎完全不一样。其他位置都具有很大的相似度。
先抛开编辑区不看,我们认为编辑区在当前阶段是不适合去抽象和统一的。再看看其他部分的细节分歧分别在哪里,
UI布局分歧:
除了编辑区之外,各品类的UI主要都由头部栏,工具栏,底部栏,右键菜单几部分组成,这几部分的位置和渲染方式也是基本一致的,从上到下都是头部栏,工具栏,底部栏。它们的分歧点一方面在于各品类会有一些独有的UI布局,比如doc和slide左边有目录,sheet底部有sheetsbar等等。另一方面,它们头部栏和工具栏里的细节不一样,比如doc和流程图的头部栏有播放按钮,但sheet没有播放功能。各个品类工具栏中放置的按钮相差也比较大。
feature(功能特性)使用分歧:
各品类使用的feature种类大部分是相同的,比如都需要设置权限、登录等等。但不同品类可以有一些个性化的要求,比如在tob环境使用的feature要少很多。另外,feature还存在这样一些分歧:它们对应的代码地址,加载方式(同步加载、异步加载、闲时加载、点击按需加载等等),是否需要沙箱等等。
service(服务)实现分歧:
经过合理的抽象封装后,许多服务都可以供各品类同时使用。但各品类依赖的服务也总会一些差异,比如doc和sheet的协同冲突处理服务会有一些局部的差异,这些产品特性上的差异是无法单纯用抽象封装的方式来抹平的。在多端环境下也会存在不少service的实现分歧,比如企业微信下的js-bridge和腾讯文档app下的js-bridge就是由两套代码来提供服务的。
动态运行时逻辑分歧:
前面的3种分歧都是属于静态分歧,在产品需求定好之后,这些分歧我们就可以分析出来,且在代码的编译期就可以处理好这些分歧。但有一些分歧,是在特定的环境下,在代码动态阶段才能得知的,比如有这样一个需求,doc的工具栏在pc端宽度小于800px时会触发一些特殊逻辑,比如将某些组件收折起来。用if,else当然能处理这些场景,但这种if、else是一种完全违反开放-封闭原则,扩展性非常差的方式,我们仍然需要找到一个更好的方式来处理这些动态运行时逻辑分歧。
生命周期和启动流程分歧:
在一个大型项目中,给业务设置固定而合理的生命周期是非常必要的。我们设定一些规则,让某些业务流程和某些生命周期绑定起来。这些关系约束,可以让业务流程更稳定的流转下去。但同一套生命周期和启动流程无法满足所有品类&租户,总有些情况下,我们需要让当前系统拥有一些个性化的生命周期和启动流程。
多宿主&终端分歧:
现在我们有7个品类和多个终端(pc,web,ipad),代码可能还运行在多个宿主里(腾讯文档客户端,企业微信客户端,小程序等)。在各个宿主&终端下会有一些产品实现方面的细节差异,这些宿主&终端提供给业务代码的服务能力也可能是不一致的。
在实际开发中,这种场景下难免会需要使用条件分支控制业务逻辑的走向,但这些条件分支是违反开放-封闭原则且无法收敛的,我们需要寻找一些方式减少过多条件分支对程序的破坏。
编辑器分歧
各品类的编辑区产品体现是非常不一样的。前面也说明,暂时没有必要花太多力气尝试去抽象和统一各个品类的编辑器,但我们依然需要一种方式,能把各种各样的编辑器,以简单而一致的方式接入到腾讯文档中。
其他细节分歧
上面是一些各品类间的固定分歧,此外,在实际代码编写中,还会遇到很多实现上的细节分歧。比如创建对象分歧、逻辑执行分歧、子服务组成分歧、新旧数据兼容分歧、模块通信分歧等。这些细节分歧可以用一些if、else之外更适合的方式来解除。
如何解决分歧:
当我们找出各品类之间的分歧之后,剩下的就是寻找合适的方式去逐个解决它们。这些方式都需要满足几个特点:
- 抹平分歧的代码,也是最不稳定的代码。尽量让它们处在系统的低层位置
- 在消灭分歧的过程中,需要让整个系统尽量遵循开发-封闭原则,禁止使用if、esle或者使用复制粘贴技能
解决UI布局分歧:
每个品类&租户的腾讯文档,可能都会有自己个性化的UI布局需求,首先这些产品体验上的差异分歧,是无法直接消除或者忽略的。其次,UI布局的变化频率是最快的。解决UI布局分歧最好的方式是能通过配置文件去描述和绘制页面中对应的UI。
团队的ziofatli同学之前开发了一套针对腾讯文档的UI布局框架 - workbench,workbench正好能完美解决这个问题,它包含了一系列与业务逻辑无关的代码配置文件,第一个配置文件描述页面中组件的父子关系,其他文件分别负责绘制每个UI的样子。
1 | import { WorkbenchMenuSchema } from '@tencent/tdoc-ark'; |
1 | import { MenuConfig } from '@tencent/tdoc-ark'; |
这些文件组合起来,结合一系列规则,便可以绘制出腾讯文档里所有UI按钮.
解决feature(功能特性)使用分歧:
我们考虑下,当我们在开发一个新品类。它将会如何使用“权限设置”和“查找替换”这两个 feature呢,它可能有下面这些不同的使用诉求呢?
- feature是否需要
- feature对应的代码地址不同
- feature的加载方式不同,权限设置是点击按需加载,查找替换是闲时加载(跟权限设置不同,查找替换是可以脱离网络离线使用的,所以为了避免使用时没有网络的情况,我们需要在首屏后的浏览器空闲时间尽快将它加载下来)
- 是否需要沙箱,使用哪种沙箱的策略不同
- 父容器节点不同
- feature与其他feature之间的依赖关系不同和之间的映射关系不同
- UI和feature之间的映射关系不同
这几种分歧很明显都可以用静态代码来表达,所以我们也可以将这些分歧都放置在配置文件里。
1 | import { IExtensionDescription } from '@tencent/tdoc-ark'; |
解决service(服务)实现分歧:
虽然我们尽量将模块和服务封装成通用,希望它们能被所有消费者公用。但在现实代码中,各品类对于某些服务的实现是有比较大的分歧的,同一份底层代码在不同品类间切换的时候,我们希望能迅速将一个服务替换为另外一个服务,这个过程不会影响其他模块。
举个例子,假设腾讯文档各品类的协同冲突处理模块,流程和大部分模块都是通用的。
流程如下:
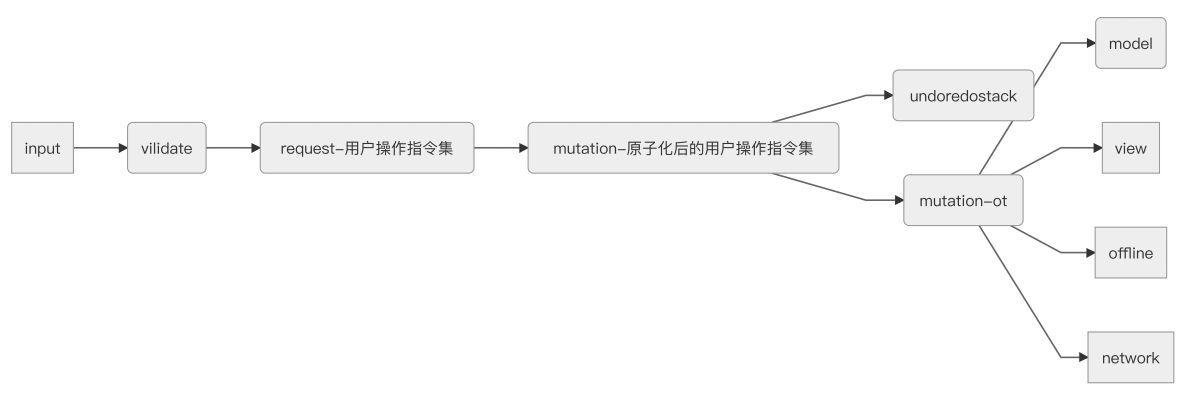
其中通用的部分主要是模块依赖顺序和代码执行流程,可以用一个模版方法来表达:
- 接收用户输入
- 对用户数据进行校验
- 将用户输入数据转化为request
- 将request转化为mutation
- 将mutation放入undoredo栈
- 同时对mutation进行ot运算,得到冲突处理之后的mutation
- 将最终的mutation结果分别写入数据层、渲染层、离线层、网络层
这些流程都是一致的,所以我们很容易编写一个各品类公用的冲突处理模块。
但vilidate、request、mutation的相关服务是无法各品类公用的,因为各品类都有自己的数据校验逻辑,也有表现和功能各异的request和mutation,这意味着当我们在使用通用冲突处理模块的时候,必须让各品类来提供自己的vilidate、request、mutation这几个相关模块的服务。
也就是说,我们要解决各个品类关于vilidate、request、mutation这几个模块服务的实现分歧。
解决这个问题的办法是就是面向抽象编程。
面向抽象编程
抽象的意思是,从一些事物中抽取出共同的、本质性的特征。面向抽象编程有很多方法,其中最重要的是用接口来表示抽象,面向抽象编程在这种情况下,就是指面向接口编程。我们要让模块与模块之间的关系,从依赖具体实现变为依赖抽象接口。
之前我在其他文章里举过一个简单的例子来介绍面向抽象(接口)编程。这里再顺便快速回顾一下。
在某段核心业务代码里,需要利用 储存一些用户的操作信息,代码很快就写好了:
1 | import localstorge from 'localstorge'; |
这段代码本来工作的很好,但是有一天,我们发现用户信息相关数据量太大,超过了 localstorage 的储存容量。这时候我们想到了 indexdb,似乎用 indexdb 来存储会更加合理一些。
现在我们需要将 localstorage 换成 indexdb ,于是不得不深入 User 类,将调用 localstorage 的地方修改为调用 indexdb 。似乎又回到了熟悉的场景,我们发现程序里,在许多核心业务逻辑深 处,不只一个,而是有成百上千个地方调用了 localstorage, 个简单的修改都成了灾难
所以,我们依然需要提取出 localstorage 和 indexdb 的共同抽象部分,localstorage 和 indexdb 的共 同抽象部分,就是都会向它的消费者提供一个 save 方法,作为它的消费者,也就是业务中的这些核心逻辑代码,并不关心它到底是 localstorage 还是 indexdb,这件事情完全可以等到程序后期再由更外层的其他代码来决定。
我们可以申明一个拥有 save 方法的接口
1 | interface DB{ |
然后让核心业务模块 User 仅仅依赖这个接口:
1 | import DB from 'DB'; |
接着让Localstorge和Indexdb分别实现DB接口:
1 | class Localstorge implements DBc{ |
这样一来,User模块从依赖Localstorge或者Indexdb这些具体实现,变成了依赖DB接口,User模块成了一个稳定的模块,不管以后我们到底是用Localstorge还是用Indexdb,User模块都不会被迫随之进行改动。
我们说的面向抽象编程,通常是针对核心业务模块而言的。User模块是属于我们的核心业务逻辑,我们希望它是尽量稳定的。不想仅仅因为选择使用Localstorge还是Indexdb这种事情就得去改动User模块。因为User模块这些核心业务逻辑一旦被不小心改坏了,就会影响到千千万万个依赖它的外层模块。
如果User模块现在依赖的是DB接口,那它被改动的可能性就变小了很多。不管以后的本地存储怎么发展,只要它们还是对外提供的是save功能,那User模块就不会因为本地存储的变化而发生改变。
相对具体行为而言,接口总是相对稳定的,因为接口一旦要修改,意味着具体实现也要随之修改。而反之当具体行为被修改时,接口通常是不用改动的。
回到腾讯文档业务,虽然每个品类所需要的vilidate、request、mutation这几个服务的具体实现不一样,但它们还是能抽象出很多共同点,比如这些服务中含有的public方法都是一样的。我们可以为这些public方法建立抽象接口。然后让其他上下游去依赖这些抽象接口。这些抽象接口是很稳定的,不会因为处在不同品类中而产生变化,所以我们整个模块也变得稳定。
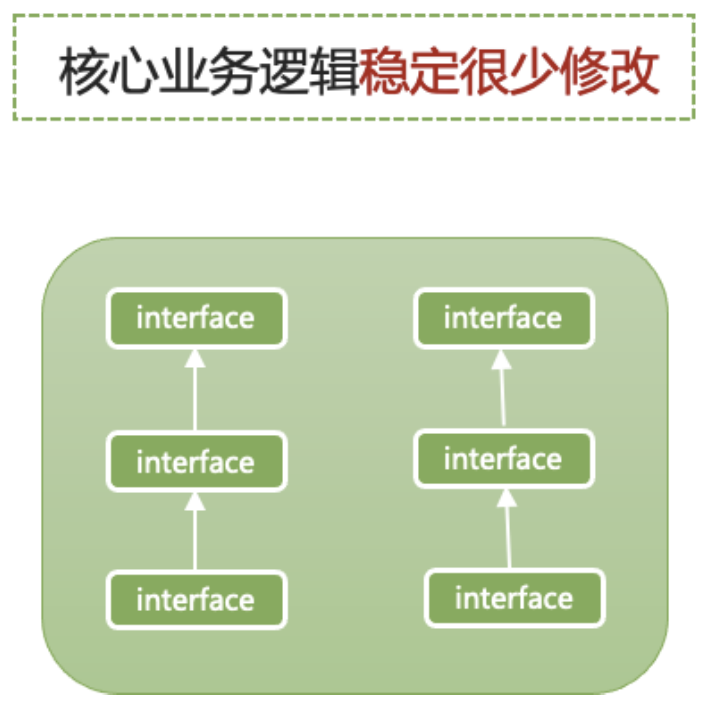
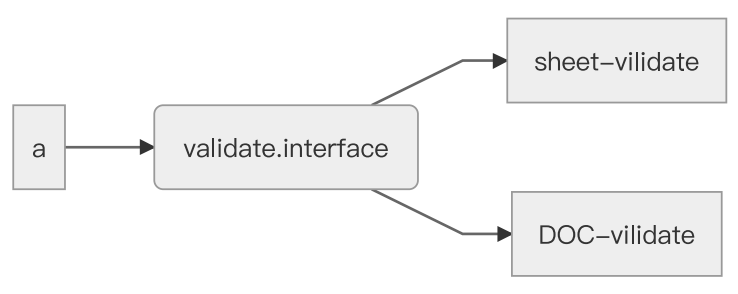
程序在编译期依靠同一个interface通过了类型检查,但在运行时,如何能指向正确的服务呢?比如在sheet里这个接口对应的真实服务分别是sheet-vilidate,sheet-request,sheet-mutation,而在doc里,对应的真实服务分别是doc-vilidate,doc-request,doc-mutation。
所以,我们还要想办法,将真实的服务传入引用了这个接口的消费者,让接口和具体服务绑定起来,提供给消费者使用。
这里我们利用依赖注入能力完成接口与具体服务的映射和关联。可以看到,我们在构造函数里申明的模块与模块的依赖关系,并不是指具体的某个类,而是指向的某个接口。

在其他系统的低层位置,我们会去真正的绑定接口和具体服务的关系。
1 | const serviceRegistry = new ServiceRegister(); |
当我们需要替换服务时,只需要在register.ts里替换掉整个服务就可以了,其他高层代码不需要进行任何改动。
在腾讯文档的最终形态中,而每个品类会有一个自己的register.ts,负责注册自己所需的服务,在不同品类之间使用不同服务,只需要修改接口与服务之间的映射关系。我们利用这套机制来消除各品类间服务的实现分歧。
处理动态运行时逻辑分歧:
虽然if、else条件分支是一种违反开放-封闭原则,扩展性不好的方式。但少量程序中的动态运行时分歧,我们也不反对耦合使用if、else来处理这些分歧。但在腾讯文档和vscode这种大型项目中,问题总是成倍数放大。
为了不让程序中充斥if,else语句,我们参考vscode处理同类问题的方案,采用表达式配置来处理动态运行时分歧。

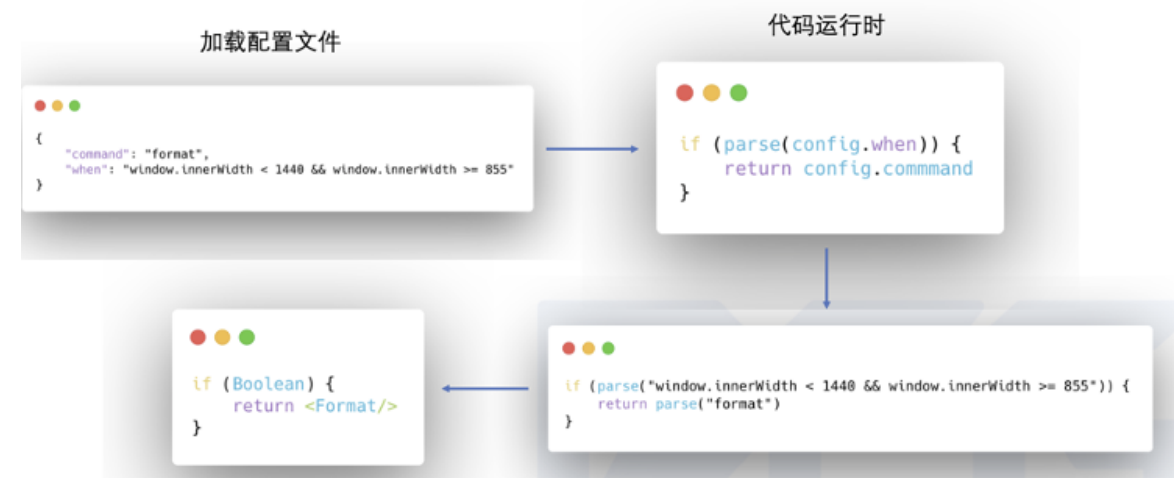
处理多宿主&终端分歧:
现在我们有 7 个品类和多个终端( pc,web,ipad ),代码可能还运行在多个宿主里(腾讯文档客户端,企业微信客户端,小程序等)。在各个宿主&终端下会有一些产品实现方面的细节差异,这些宿主&终端提供给业务代码的服务能力⻚可能是不一致的。在实际开发中,难免会需要使用条件分支控制业务逻辑的走向
1 | if (sheet){ |
而这些条件分支是违反开放-封闭原则且无法收敛的,我们需要寻找一些方式减少过多条件分支对程序的破坏。
首先给每个终端一个 main 入口,如:
1 | // pc 端 entry/pc.ts: |
1 | // mobile 端 entry/mobile.ts: |
ArkProcesson 里加载不同端对应的不同配置文件:
1 | // pc 端 |
不同的配置文件指向不同端的 service :
1 | // pc端: |
1 | // mobile端: |
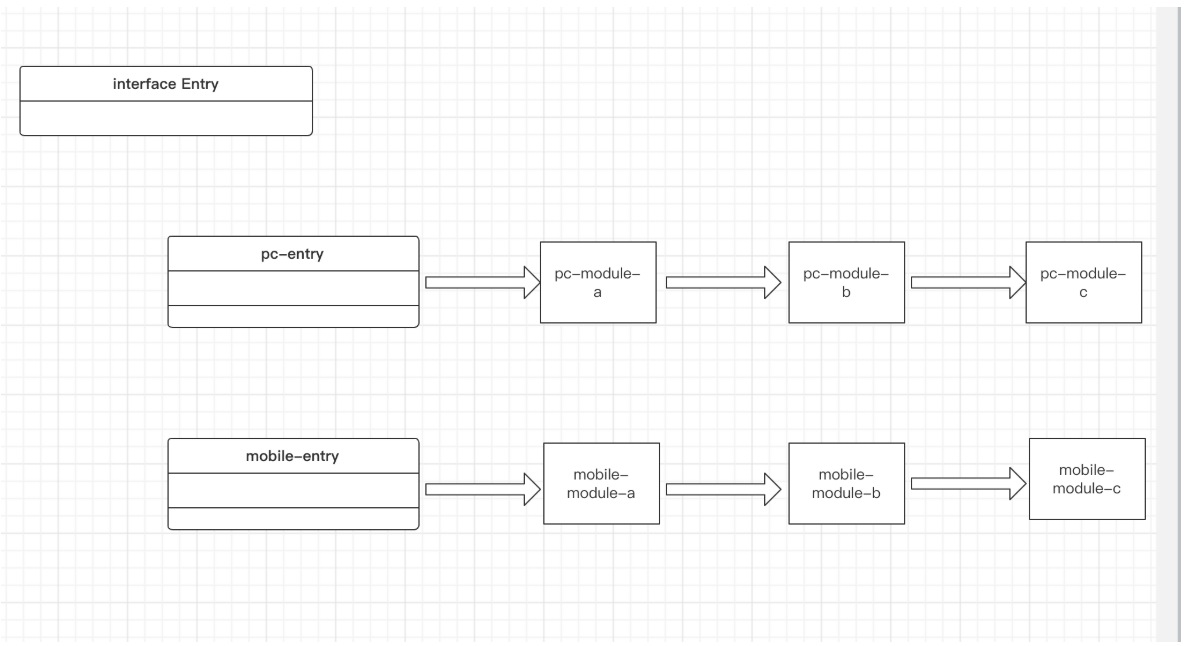
我们从为每个端提供不同的入口,在入口处就给它们分别分配了不同的service实现,各个service之间的依赖关系都是通过interface联系起来的,而这些service都运行在各自终端环节下,永远不会交叉。
就好像当程序进入到不同端的入口中,就进入了不同的平行世界,平行世界的运转规则是完全一样的,它们可以通过共同的抽象interface联系起来。但平行世界里的实体是不同的,每个端下面有自己的对应实体。
这是service粒度的分歧解决方案,在service内部,我们也可以用粒度更小的多态或者依赖倒置等方式来解决品类和终端之间更细节一些的分歧,后面会有例子提到。
处理生命周期和启动流程分歧:
腾讯文档的应用启动流程也非常复杂,从大的层面看,有基础服务层、数据层、渲染层、UI绘制层、插件层等等层级模块要分别启动。每个层次之间又可能含有n个子服务。
在这些复杂的业务中,给业务设置固定而合理的生命周期是非常必要的。我们设定一些规则,让某些业务流程和某些生命周期绑定起来。这种约束关系可以让业务流程更稳定的流转下去。也很容易对某些模块的启动成功情况和启动耗时等信息在生命周期内进行进行统一监控和上报。
但同一套生命周期和启动流程无法满足所有品类&租户,总有些情况下,我们需要让当前系统拥有一些个性化的生命周期和启动流程。于是我们在默认生命周期基础上,扩展了自定义生命周期,用户可以根据自己业务的情况来创建和绑定自定义生命周期。
同时我们开发了一套基于job+task的任务调度器机制,将各品类公用的一些启动流程封装成默认的job+task,业务开发者可以选择相应的job或者task,结合生命周期一起,完成自己的启动流程。
一个品类启动应用最终需要做这些事情:
- 新建一个entry入口,entry作为main函数,负责启动调度和管理其他模块的初始化
- 选择一些默认task+job,或者自己新建task&job,作为应用启动的必须参与模块
- 通过生命周期启动应用
代码大致如下:
1 | // 自定义生命周期 |
编辑器分歧
各品类的编辑区产品体现是非常不一样的。前面也说明,暂时没有必要花太多力气尝试去抽象和统一各个品类的编辑器,但我们依然需要一种方式,能把各种各样的编辑器,以简单而一致的方式接入到腾讯文档中。
我们利用了团队 ziofatli 同学开发的 workbench 框架来达成这件事情,workbench 框架是为文档 型应用设计的一个工作台框架,其中提供了适配器将文档编辑器和其他部分连接起来。

Workbench 提供了一个 Adapter 接口,要求对应的编辑器 SDK 去实现这个接口,工作台就能保持一致的方式去操作各个编辑器。
同时,在挂载一个新的编辑器时,也会传入一个新的 Adapter Callback 对象,要求 Adapter 在特定时机去调用其中的指定方法,比如聚焦、失焦、选区和数据变化的时候,这样工作台就 可以通过 Surface Service 了解所需要的当前编辑器的状态。
这个 Adapter 实际上是一个 mediator 中介者, mediator 知晓编辑器和文档其他部分的所有信息,所以可以将双方的服务按照需要一一绑定起来。
下面是我们几个品类分别通过来绑定编辑器的代码:
流程图
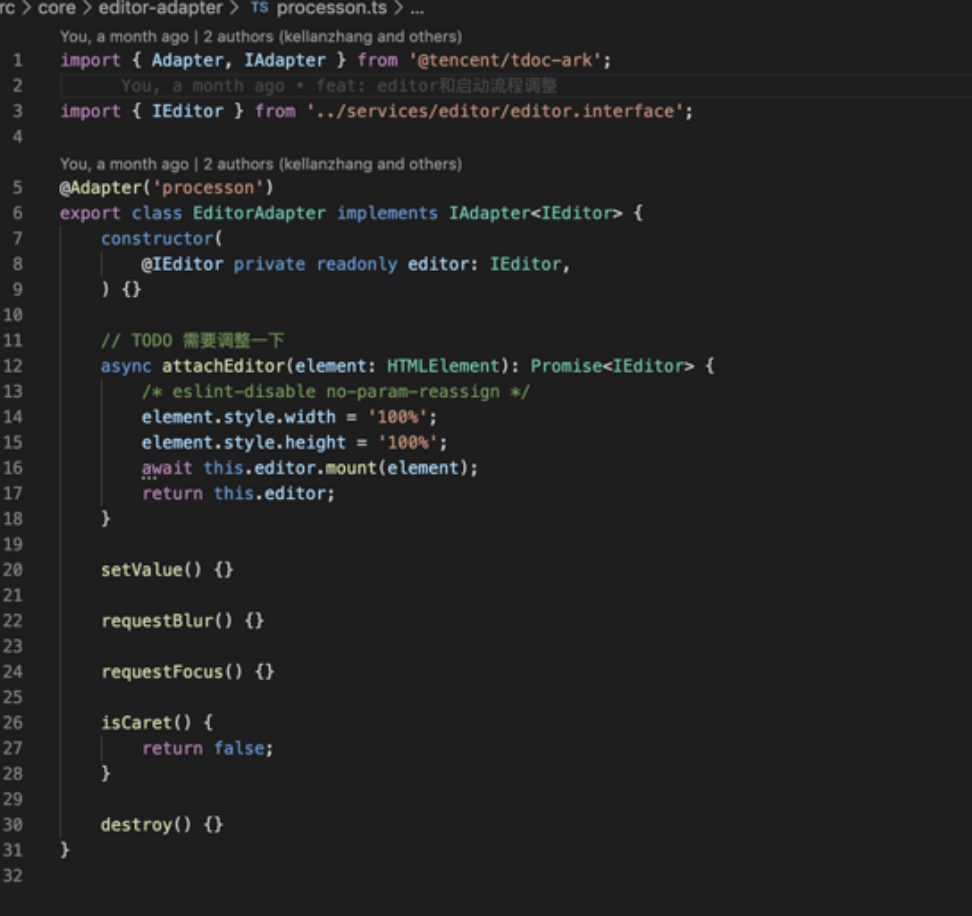
sheet
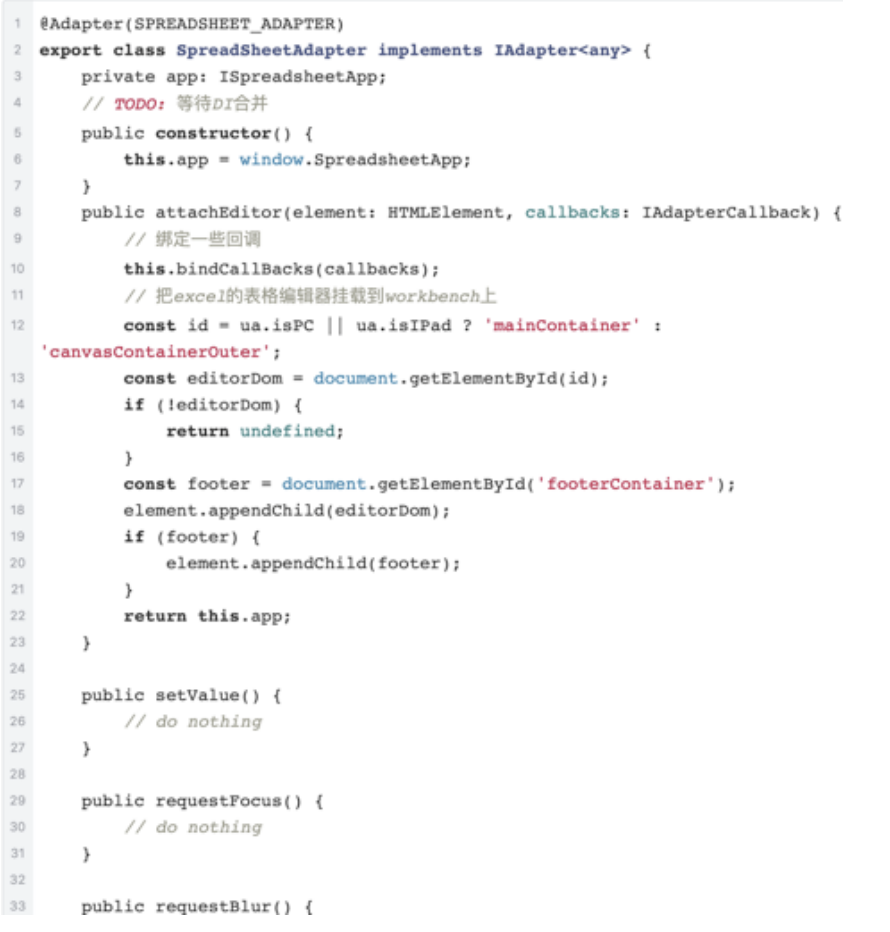
doc

总结
前面介绍了我们如何通过一系列的方式来解决各个品类之间的各种分歧,使得各个品类之间可以顺利的复用代码和知识。这里思考的关键是我们要如何分别找出各个品类之间的共性和分歧,然后将共性封装起来,放在系统稳定的高层位置,再将分歧提出出来放在系统的低层位置,随后用一些方法来解决各品类之间的分歧。
虽然这些分歧永远不会消失或者减少,但通过这些手段,我们可以在需求变更来临的时候付出的代价变得更小,程序员的工作也更轻松。
其他细节分歧
在实际代码编写中,除了上面这些大的分歧之外,我们还可能遇到很多实现上的更细节分歧。这些细节分歧没有必要提供统一方案来处理,我们在代码中根据实际情况来抹平就可以。
比如:
创建对象分歧
- 除了依赖注入之外,一些小的创建对象的分歧一般可以用工厂方法或者抽象工厂解决
子服务组成分歧
- 用facade来包裹子服务分歧,对上层消费者提供统一的调用方式
模块通信分歧
- 用command扩展点或者中介者模式解决
逻辑执行分歧
- 用命令模式或者回调函数解决
新旧数据兼容分歧
- ACL层或者PROXY解决
最后一些临时分歧,在需求比较紧张的时候,我们也允许通过评审后的一些if、else来解决,虽然不是很赞同这种临时方案,但也确实要理解,在现实和理想取的平衡之时,我们也允许系统中留下一些技术债务,当然我们也要确保这些技术债务不出现在系统的最重要位置,也不会过多影响系统以后的迭代。
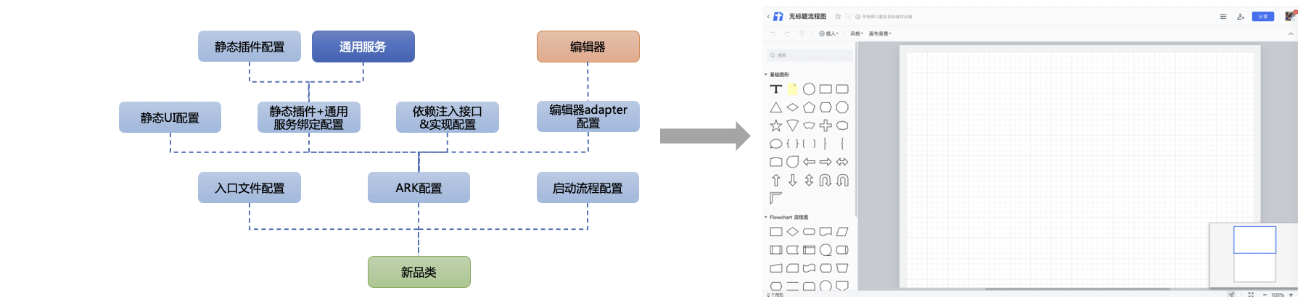
我们将整套解决方案,包装成tencent-ark框架,除了一些细节分歧在代码内部处理之外,一个新品类的接入,大致可以分为8份配置文件 + 通用服务 + 编辑器的组成。