腾讯文档前端架构思考和实践(三)-依赖注入实践和改造
依赖注入是一种常见的优化和管理模块&class 依赖关系的手段, 在介绍依赖注入对之前, 我们先思考下, 造成项目中模块依赖混乱的原因有哪些? 除了没有仔细思考和整理模块之间正确的依赖关系之外, 创建对象和获取对象的复杂性也是一个重要原因。
在某些模块中创建或者去获取另外一个对象都是很常见的操作, 但这些操作其实是相当麻烦的一件事情。 对象的创建可能需要传递很多参数, 为了在创建时得到这些参数, 我们又可能需要去其他各种地方寻找这些参数, 并将这些参数相关的类都引进来, 这就造成了很多不必要的依赖。
除此之外, 我们还必须手动保证这个类需要的所有对象都能被正确的创建出来, 当对象与对象有嵌套关系时, 还要手动去保证它们分别被创建的顺序, 当依赖关系很复杂时, 创建一个对象之前需要先创建好无数个它依赖的其他对象。就好比一个早点师, 本来他只关心怎么使用面包机来烤熟面包。 但是现在在使用面包机之前,他还要先了解面包机的制造过程, 以及从哪里才能得到黄油和面粉, 甚至还要知道水稻是怎么种出来的。
每当要创建一个复杂对象时, 心理感受都类似于打开电视机前, 还要先找出一堆电源线并将它们插在墙壁上:

再看一些具体的代码, 可能会理解的更深刻一点:
比如在 class A 和 class B 里都需要引用 class C 的对象 c。 这时候的依赖关系理应是相当简单的。
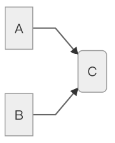
但是对象 c 的创建又需要 3 个参数对象, 分别是对象 d、 对象 e、 对象 f。 所以我们为了创建出对象 c, 先得想办法弄到对象 d、 e、 f。
伪代码:
1 | import d from 'd' |
1 | import d from 'd' |
此时依赖关系变成了:
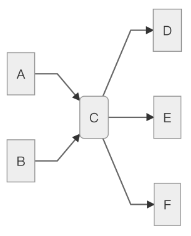
此时如果对象 d 又依赖对象 h、 i、 g 呢? 本来 a 和 b 只需要关心 c 就可以了, 但因为 c 的创建又必须依赖 h、 i、 g, b、 x, y, z。 导致最后 a 和 b 都需要依赖这么多本可不产生任何联系的类。 这里就会形成一个很大的依赖树, 甚至有可能出现循环依赖。
出现这些问题的关键是: 我们没有将对象的创建和对象的使用分开。 对于模块 a 和 b 来说, 它其实只想使用 c 对象, 它对 d、 e、 f 对象是什么在本质上是毫不关心的。 a 和 b 只关心 c 对象怎么使用, 它们不应该关心 c 对象是如何被创建出来的。
就像早点师只关心面包机怎么使用, 他没有必要去了解面包机是通过哪些材料制造出来的。
腾讯文档曾经使用的办法:
为了解决创建对象不方便的问题, 我们曾经在 sheet 项目中, 在全局挂了一个 speadSheetApp 对象。
所有经常被其他模块依赖的对象, 比如网络层、 离线层、 数据层、 渲染层等都可以在系统的启动阶段就创建好, 然后直接挂在这个对象上。
这样一来, 谁想调网络层、 离线层、 数据层,不需要再重新和额外创建它们, 只要从 speadsheetapp 对象上拿就可以了。
但这样一来, speadSheetApp 就变成了一个超级大的上帝对象, 模块之间真实的依赖关系都被隐藏在 speadSheetApp 后面。
而且为了优化首屏性能, 我们将很多模块都做成了懒加载, 在 speadSheetApp 对象外面, 无法得知当中某个模块是否已经真实加载完, 项目里充斥着 speadSheetApp?.x?.y?.z 这种保护代码。
依赖注入的实现思路
将所有对象都挂在全局的方式显然是不可取的, 依赖注入的目的, 就是为了解决创建对象繁琐而复杂的问题。
依赖注入的思路是引入一个容器类, 让容器去统一管理对象的创建。 容器会自动解析类与类之间的依赖映射关系, 并将这些映射关系存放在容器内部。 在消费者需要的时候, 容器再按需动态创建相应的对象提供给消费者使用。
对于对象的消费者来说,不用再关心它依赖的对象是怎么创建出来的, 它们只管向容器要这些对象, 然后使用即可, 所有对象的创建过程都由容器来统一负责。
依赖注入最大的优点是将对象的创建过程与对象的使用过程分开, 消费者只管拿到对象开始使用, 消费者不再关心对象究竟经历了哪些繁琐而复杂的创建过程。
就好比面包师不再关心面包机和制作面包的材料是哪里来的, 他需要伸手, 便有人将这些东西准备好。
即使对于前端, 依赖注入也不是一个新的概念,业界有 nestjs、 midway、 inversifyJS 等成熟的依赖注入框架, angular 和 vscode 等优秀的开源项目也大量使用了依赖注入技术。
依赖注入在 ts 里的实现这里不准备详细介绍, 大致思路分为这两步:
利用 ts 装饰器, 将 class 的信息和所它依赖参数对象的映射关系收集起来, 形成一个有序无环图存放在容器内部
当消费者需要使用某个对象时, 容器会从这个对象的依赖根节点开始创建一批对象, 直到这个对象完整可用, 并将这个对象提供给消费者。
如下图所示:
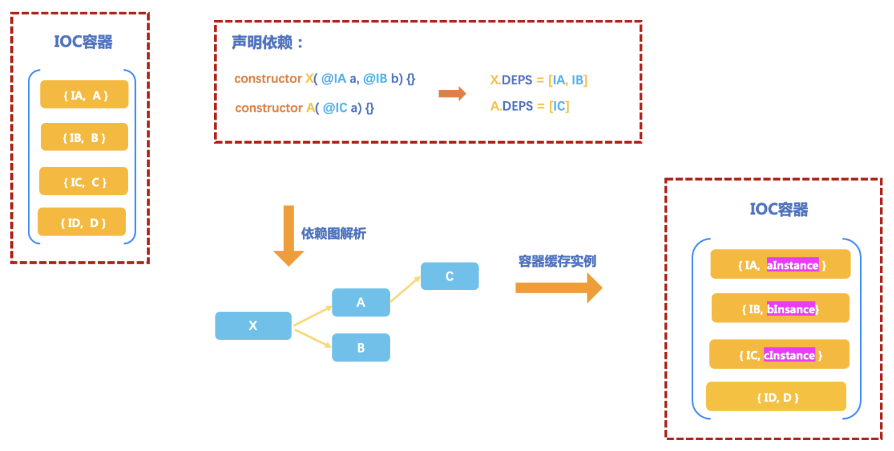
由于这些参数对象都不是在 class 里由消费者亲自创建的, 而是由容器创建并提供给消费者使用。这些参数对象看起来是由 class 的外部注入进来的, 所以这种技术被称之为依赖注入。
腾讯文档依赖注入选型
前面说过,业界已经有众多成熟的依赖注入框架, 但腾讯文档没有直接使用这些框架, 而是选择改造了 vscode 里的依赖注入模块。 主要原因是, 除了需要用依赖注入来管理模块关系之外,因为腾讯文档的业务特性, 我们还希望依赖注入框架能为我们解决这些问题:
支持异步模块依赖
- 腾讯文档前端代码量巨大, 理论上有 90%以上的模块都最好用异步加载的方式来引入, 为了减轻使用者的理解和维护负担, 我们希望可以和同步依赖注入一样, 用统一的依赖注入方式来表达模块的异步加载逻辑。
支持容器化销毁&复用
- 腾讯文档是个非常大的单页面应用, 为了保持内存维持在一个低水平线, 我们需要持续对页面中不再使用的对象进行清理, 依赖注入容器也许能帮助我们快速和方便的完成这件事情。
支持对象延迟初始化
- 同样是从性能考虑, 页面里有部分模块需要被提前加载进来, 但是没有必要在刚加载好之后就初始化它们, 比如 undoredo 栈这个模块, 是完全可以等到真正产生用户操作行为之后才初始化的。
帮助构建单向依赖系统
- 腾讯文档有成百上千个模块 class, 我们不希望这么多对象都放到同一个容器里, 而是希望容器可以同时存在多个, 而且容器与容器之间可以分层依赖, 即某些容器里的对象可以访问另外一些容器里的对象, 但反过来希望能拒绝掉模块之间的访问, 这个特性可以帮助我们构建一个真正的单向依赖系统。
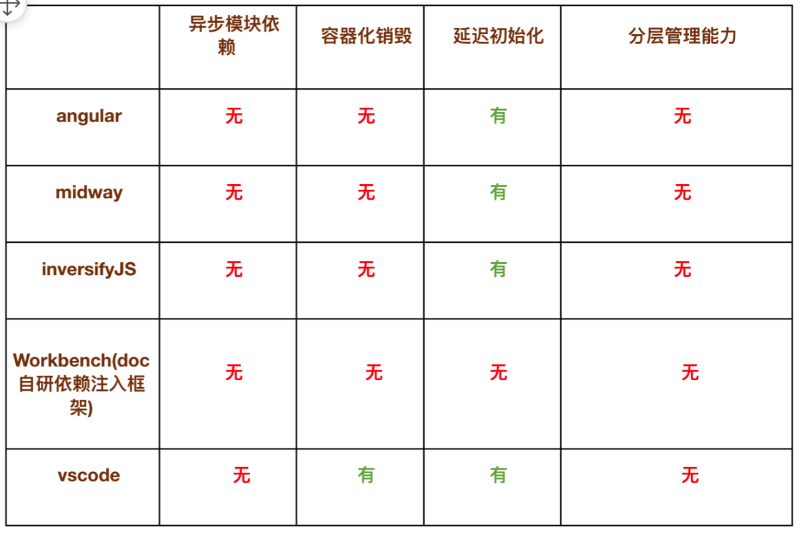
市面上这些框架都不能完全提供这 4 种能力。
其实背后的原因也不难理解。 因为它们都是一些通用框架,不是为腾讯文档这种特殊业务准备的。 框架的开发者和使用者都很少会直接面对腾讯文档前端这种极限复杂的业务。
容器化销毁、 分层管理、 异步模块依赖对他们来说, 并不是特别重要, 所以不提供这些能力反而是正常的。
好在 vscode 跟腾讯文档有几分相似, vscode 也是一个大的单页面业务, 在不同的 tab 切换时,vscode 的性能表现非常出色, 我们猜测它提供并使用了容器化销毁&复用能力。 后来通过阅读 vscode 依赖注入的源码也验证了我们的想法。
但 vscode 主要作为 native 客户端运行在桌面上, 它对于异步加载的诉求不是很强烈, 所以它没有提供异步模块依赖的支持。
最终我们选择借鉴 vscode 的依赖注入模块, 来改造腾讯文档所需的依赖注入能力。 vscode 依赖注入模块的核心代码非常少, 只有 200 多行, 代码越少我们改动起来的心里负担自然也越少。
vscode 的依赖注入实现和其他框架的思路都大同小异, 主要都是由这两步组成:
利用 ts 装饰器, 将 class 的信息和所它依赖的参数对象的映射关系收集起来, 形成一个有序无环图存放在容器内部。
当消费者需要使用某个对象时, 容器会从这个对象的依赖根节点开始创建一批对象, 直到这个对象完成可用, 并将这个对象提供给消费者。
稍有不同的是,vscode 的 api 更加简单,只提供了构造函数注入能力。现在我们开始给 vscode 依赖注入模块扩展我们需要的能力
异步模块依赖注入:
在此之前, 再稍微讨论下为什么腾讯文档需要异步模块依赖注入。 毕竟往常我们写一些异常加载模块的过程也不复杂, 比如:
伪代码:
1 | class A{ |
我们经常用上面这些代码来编写含有异步逻辑的程序。 但是这种方式是由一些明显的问题的。
对于 a、 b、 c 这几个对象, 我们在阅读和维护这个类的时候, 通过构造函数便知道它依赖了 a、b、 c, 这时候可以放心的使用 a、 b、 c, 但我们不知道 userinfo 会由谁去加载、 它究竟在什么时候才能加载好, 它的加载时机被埋藏在业务逻辑内部, 取决于业务逻辑的执行结果。这种异步逻辑的处理会影响业务开发者对于程序的阅读和理解。
而腾讯文档理论上有 90%的模块都是可以通过异步加载的 这么多的异步加载模块会对代码的
可读性和可维护性产生不少冲击。 前端代码中, 对异步逻辑和同步逻辑的处理还是有蛮大的区别, 特别是一些嵌套的异步处理场景会更加麻烦, 开发者要将 90%的异步模块和 10%的同步模块很好的融合在一起是不太可能的, 对异步模块的加载和处理一般都散落在业务逻辑中, 在很多异步模块和很多同步模块混杂在一起的时候,业务开发者很难看清它们的依赖关系。
我们希望框架能帮助对上层业务开发者抹平差异, 开发者可以用同样的视角去对待异步模块和同步模块, 可以很大程度上减轻业务开发者在处理异步模块和同步模块分歧上的痛苦,上层业务开发者尽量少去关心依赖注入的模块是同步还是异步, 能将精力更多的集中在业务逻辑里。
异步依赖注入实现原理:
这里原理既简单又比较巧妙, 主要由团队的 kellanzhang 同学完成。
首先我们在 api 层增加了一个 dynamicLoader 模块来表示异步模块依赖, 当依赖图中存在这些异步依赖时, 并会将一个依赖图切成两个依赖图, 中间的异步依赖用一个桥接模块来连接。 当解析依赖时遇到了异步模块之后, 由这个中间的桥接模块要负责解析和加载异步模块, 并将它们拼成一个整的依赖图。 利用同一个原理, 我们还扩展了闲时加载依赖、 worker 加载依赖等依赖注入方式。
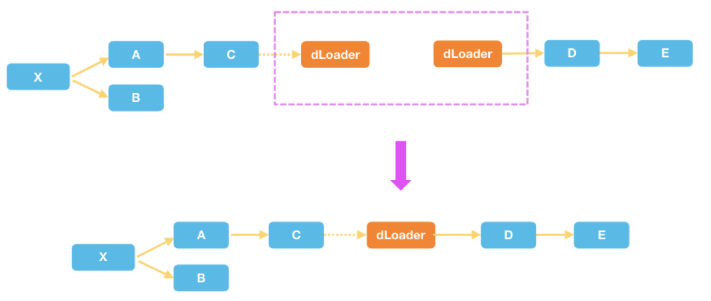
通过引入dynamicLoader,我们屏蔽了同步和异步模块的实现细节; 一个模块是同步还是异步, 只需要在声明依赖和注册模块时稍有差异。 业务开发者可以用同样的方式来声明和对待同步模块和异步模块, 很大程度上减少了业务开发者的理解和维护成本。

扩展其他模块加载依赖注⼊⽅式:
从业务的极致性能出发,我们依照同样的思路,以相似的api,扩展了以下这些模块加载⽅式.
闲时加载依赖注⼊:
主要⽤于⼀些重要但不紧急的模块,⽐如查找替换模块。⽤户⼀般不会第⼀时间去使⽤查找替换功能,所以这些模块是不需要赶在⾸屏显示出来之前加载的。但也不能晚到⽤户点击时才去加载这些模块,为了避免在点击加载时遇到⽹络不可⽤⽆法下载资源的情况,我们最好是利⽤浏览器的空闲时间在⾸屏之后找机会去下载这些模块利⽤requestidelcallback和settimeout,我们扩展了闲时加载依赖注⼊能⼒,让业务开发者可以⽤同样的⽅式去声明和使⽤同步加载模块和闲时加载模块,开发者不⽤在具体业务逻辑中去关⼼这个模块属于同步加载还是闲时加载,只要在模块声明的时候加以区分就可以了。
worker加载依赖注⼊:
腾讯⽂档有⼀些模块是在worker⾥运⾏的,最典型的是函数计算、查找替换这些包含复杂计算逻辑的模块,跟闲时加载依赖注⼊类似,我们也扩展了worker相关的依赖注⼊⽅式。业务开发者可以⽤同样的⽅式区声明和使⽤主线程加载模块和worker加载模块。如果业务开发者想让⼀个模块从主线程运⾏切换到worker线程运⾏,同样只需要修改⼀句声明即可。
分层管理依赖:
腾讯⽂档有成千上万个class,如果将这么多对象都放到同⼀个容器⾥,那这些对象原则上总是可以互相依赖和访问的,在尝试构建⼀个单向依赖系统的时候就会遇到很多麻烦,我们只能⽤code reviewer等⽅式让系统尽量保持单向,如果有⼀些开发者不⼩⼼或者故意违反单向依赖原则,我们也没有很好的办法去阻⽌他。⽽这是⼀种很危险的⾏为,容易形成破窗效应,最终破坏整个系统的单向依赖规则。
当然在实际开发中,让系统中每⼀个class都百分之百遵循单向依赖原则是不太现实的,毕竟代码最终是⽤来组成产品,快速交付给⽤户使⽤的。但⾄少我们可以让⼤的层级之间遵循单向依赖原则。⽐如数据层绝对不能直接访问渲染层,⼯具类绝对不能直接访问业务逻辑。
依赖注⼊容器可以辅助做⼀些事情,我们可以创建多个具有⽗⼦关系的依赖注⼊容器,然后设定这样⼀个规则:⼦容器⾥的模块可以访问⽗容器的模块,但⽗容器⾥的模块禁⽌访问⼦容器⾥的模块。这样⼀来,我们可以将系统中不同层级的模块分别放⼊到不同容器⾥,让容器来辅助它们形成单向依赖关系。

实现过程也⽐较简单,我们给vscode的添加增加了创建⼦容器功能。在系统初始化阶段就将属于不同层级的模块,分别扔进不同容器中。

当在容器⾥查找对象的时候,⼀旦发现有⼈违反了单向依赖原则(将⽗容器⾥的模块,指向了⼦容器⾥的模块),便会在运⾏期抛出异常,提示我们尽早进⾏修改。
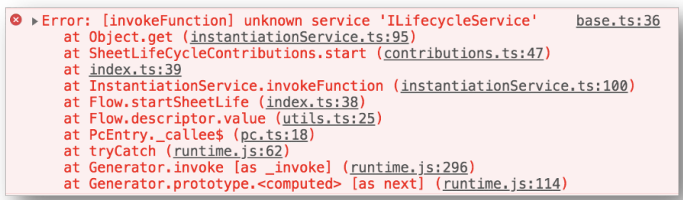
对象延迟初始化
vscode的依赖注⼊代码提供了对象延迟初始化能⼒,这个能⼒虽然实现简单,但是给业务带来的实际帮助效果⾮常不错。
系统中有⼀些对象,⽐如腾讯⽂档的undoredo模块,为了便于提供给其他模块使⽤,我们⼀般会在程序的启动阶段就初始化好⼀个undoredo对象。
如:
1 | class app { |
消费者可以随时使⽤undoRedoStack:app.undoRedoStack.push(element);
但实际上,在⽤户真正产⽣操作数据之前,⽤户并不需要使⽤undoredo栈,所以这时候是不需要提前来创建⼀个undoredo对象的。⼀⽅⾯,太早去创建这个对象,消耗的时间会影响其他更重要代码的执⾏。另⼀⽅⾯,如果⽤户⼀直没有编辑数据,那这个提前创建好的undoredo栈对象可能就⽩⽩浪费了内存。 ⼀般情况下,我们可以采取⼀些办法,来刻意控制undoRedoStack的创建时机。
如:
1 | class App { |
当消费者真正开始使⽤undoRedoStack时,需要通过app的getUndoRedoStack⽅法:app.getUndoRedoStack().push(element);
我们专⻔为消费者提供⼀个getUndoRedoStack函数,来控制undoRedoStack对象的⽣成时机,以及undoRedoStack成为单例对象。 但这种⽅式是有代价的,代价就是系统中⽩⽩多了getUndoRedoStack这个⽅法,开发者要阅读、理解和维护getUndoRedoStack⽅法,这些都是要持续付出的成本。
如果系统中有许多对象需要⽤这种⽅式来完成延迟创建对象的能⼒,那我们的系统将充斥着这些和核⼼业务逻辑⽆关的⼯⼚⽅法。
vscode结合依赖注⼊容器,⽤⼀种简单⽽巧妙的⽅式,将对象的初始化时机延迟到消费者真正需要使⽤这个对象的时候。
具体思路如下:
当vscode的依赖注⼊容器分析完class与class之间的依赖关系之后,并不会真正去创建⼀个个真实对象实例,⽽是先创建⼀些没有任何属性的空对象作为proxy代理来占位,这个空对象占⽤的资源是很少的,它占⽤掉的内存和创建它所花费的时间都可以忽略不计。

接下来需要劫持这些proxy代理的get⽅法,当消费者真正开始调⽤它想要调⽤的对象的时候,这时候才会在proxy的get⽅法⾥去new出对应的真实对象,消费者的每⼀次调⽤实际上都传递给了proxy,proxy再委托给真实对象。
伪代码:
1 | const undoRedoProxy = new Proxy(Object.create(null),{ |
这样⼀来,业务逻辑⾥就不⽤再关⼼这些对象的创建时机,它们会在真正需要的时候才被创建出来,⽤这种proxy代理的⽅式,既提⾼了⻚⾯性能,⼜能保证核⼼业务逻辑不受污染,对业务开发者也是完全透明的。
容器化销毁和复⽤
依赖注⼊容器化销毁&复⽤也是⼀种相当有⽤的技术,容器化销毁&复⽤可以帮助⻚⾯维持在⼀个较低的内存占⽤⽔平。
腾讯⽂档⻚⾯中存在成千上万个模块和对象,⽤户也喜欢同时打开多个腾讯⽂档⻚⾯,使得内存占⽤⽅⾯的挑战⼀直很⼤,业务开发者要持续对不再使⽤的对象进⾏清理。
⽐如⼀个分享组件,当⽤户完成分享流程之后,分享组件就应该被彻底销毁了。除了清理分享组件相关的dom之外,还要清理组件相关的整个对象树、被闭包所影响未被⾃动回收的⼀些变量、⼀些⽆法⾃动被回收的⾃定义事件、绑定在dom上的事件等等。除此之外,我们还要清理分享组件曾经带来的⼀系列副作⽤,如启动了但未真正执⾏的定时器、发起了但未收到回复的ajax请求等等。
除了⽤容器化销毁技术节省内存之外,我们还可以利⽤它的对象复⽤机制,帮助提⾼“打开或者切换⻚⾯”时的速度。
我们先想想,从⼀个⻚⾯跳转到另外⼀个⻚⾯的时候,有哪些步骤会影响第⼆个⻚⾯的打开时间?
从⼤的⽅⾯分为这⼏步:
http建连相关,反复对http请求进⾏建连的时间开销不⼩
html、js、css、图⽚等下载,资源下载也是很⼤的⼀⽐开销
js、css执⾏和⻚⾯渲染等等,这些开销随着模块的数量和复杂度成⽐例增加。
对于⼤部分项⽬⽽⾔,第1步和第2步都是⽐较耗时的。为了省去第⼀步和第⼆步的串⾏耗时,我们可以选择将这两个⻚⾯放到⼀个单⻚⾯内,⽐如:
- ⽤⼀个⼦的iframe来专⻔负责切换⻚⾯,当主⻚⾯加载完成之后,在背后⽤iframe将第2个⻚⾯需要的资源提前下载下来,也可以提前渲染和准备好⻚⾯供切换的时候直接使⽤。
但这种⽅式现在很少有⼈使⽤了,第⼀是因为资源消耗问题,iframe内加载和执⾏代码往往会占⽤很多内存,也会占⽤主线程的执⾏时间。第⼆是因为iframe缓存命中率问题,这相当于我们提前打开了后⾯的⻚⾯,但⽤户可能在这次操作中始终不需要使⽤后⾯的⻚⾯,那iframe提前消耗掉的资源就⽩⽩浪费了。
- ⽤微服务等形式去隔离多个⻚⾯,此时多个⻚⾯存在于⼀个⼤的单⻚⾯内。微服务跟iframe的作⽤差不多,好处是减少了⼀些iframe的创建和销毁过程,因为在同⼀个⻚⾯内,也不⽤重复去加载⼀些静态资源,但微服务除了沙箱本身的⼀些天然缺陷之外,也很难对不同微服务中的对象进⾏复⽤,还是⽆法有效减少内存占⽤问题。
总体⽽⾔,当发⽣⻚⾯切换时,常规的优化⽅式都有⼀些共同⽐较⼤的缺陷:
- 需要重新开始解析代码
- 许多共同的模块⽆法在⻚⾯间进⾏复⽤,⽐如⼯具栏、分享按钮、权限按钮等等,内存占⽤⾼
这两种缺陷导致打开性能和内存占⽤的结果都不太好, 我们理想的切换⻚⾯表现应该是这样:
js、css代码不需要重复加载和解析
- 所有模块都应该放置在同个⻚⾯内,可以⼀次性、也可以分批来准备它们所需的资源
⻚⾯中的模块能尽量复⽤,不能直接复⽤的模块即时进⾏销毁并重建
- 每个模块有销毁和重建功能,切换⻚⾯并不是真正的跳转⻚⾯,⽽是按需销毁和重建⻚⾯中的所有对象
保证模块被销毁后不遗留副作⽤,并能有效检测模块的销毁成功率
- 需要保证销毁和重建的正确性,并有相应的检测机制
如果⼀个顶层模块需要被销毁,需要遍历它依赖树⾥的⼦节点进⾏依次销毁
- 要维护模块与⼦模块之间的依赖和销毁关系
根据这⼏个⽬标,我们以vscode依赖注⼊能⼒为基础,设计了腾讯⽂档的容器化&复⽤销毁⽅案。
容器化销毁&复⽤技术是⼀种很好的提⾼⻚⾯性能,降低内存的⽅案,vscode之所以性能表现如此优异,也是⼤量使⽤了容器化销毁和复⽤技术,我们除了提供好底层能⼒之外,还需要要求业务代码严格按照容器化销毁&复⽤的规则来编写业务代码。腾讯⽂档前端计划在今年年底开始让各个模块全部接⼊容器化销毁&复⽤机制,希望届时能更好的优化腾讯⽂档性能。
值得提到的是,因为腾讯⽂档对依赖注⼊容器扩展了异步依赖注⼊(闲时依赖注⼊、worker依赖注⼊),有异步模块加⼊到依赖树之后,处理难度要⼤了很多。
我们要保证销毁包含异步模块的部分模块后,在将来还能低成本的重建整个依赖关系⽹。解决⽅案是:对于需要销毁的模块,我们⽣成⼀个Scoped Wrapper,其他模块通过Wrapper引⽤该模块,保证模块的真实实例没有被外部直接引⽤,这样就能安全的销毁掉模块实例。销毁后,其他模块通过Wrapper调⽤该模块的⽅法时,会触发通过DI框架重新初始化该模块,从⽽达到安全的重新初始化。
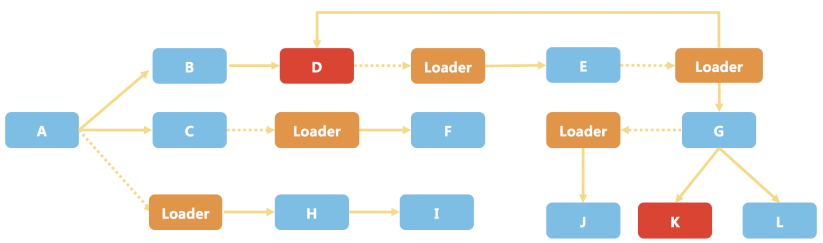
依赖注⼊总结:
刚才花了很多篇幅,来介绍腾讯⽂档如何引⼊依赖注⼊技术来改善模块之间的依赖关系。 依赖注⼊将对象的创建过程与对象的使⽤过程分开,作为消费者消费者不再关⼼对象究竟经历了哪些繁琐⽽复杂的创建过程,消费者只管拿到对象就开始使⽤,极⼤减少了开发者的⼼智负担和维护成本。
在vscode的依赖注⼊模块基础上,我们根据腾讯⽂档的业务特⾊,从性能和易⽤性⽅⾯出发,扩展了异步依赖注⼊、闲时依赖注⼊、worker依赖注⼊等功能,让消费者不再关⼼同步模块和异步模块的区别,它们可以以同样的依赖⽅式被使⽤。同时还利⽤容器化销毁&复⽤技术,提供了⼀种降低内存占⽤&提⾼⻚⾯跳转速度的⽅案。也将依赖注⼊对象的proxy延迟化技术应⽤在业务中,进⼀步提⾼业务响应速度和降低内存占⽤,还给依赖注⼊容器扩展了分层容器⽅案,来帮助我们的整个系统形成单向依赖架构。
依赖关系&依赖注⼊容器的⼀些校验:
前⾯介绍了对依赖注⼊的容器的⼀些改造,同时我们也开发了⼀些⼯具模块来对依赖注⼊相关模块的⼀些结果进⾏校验:如:
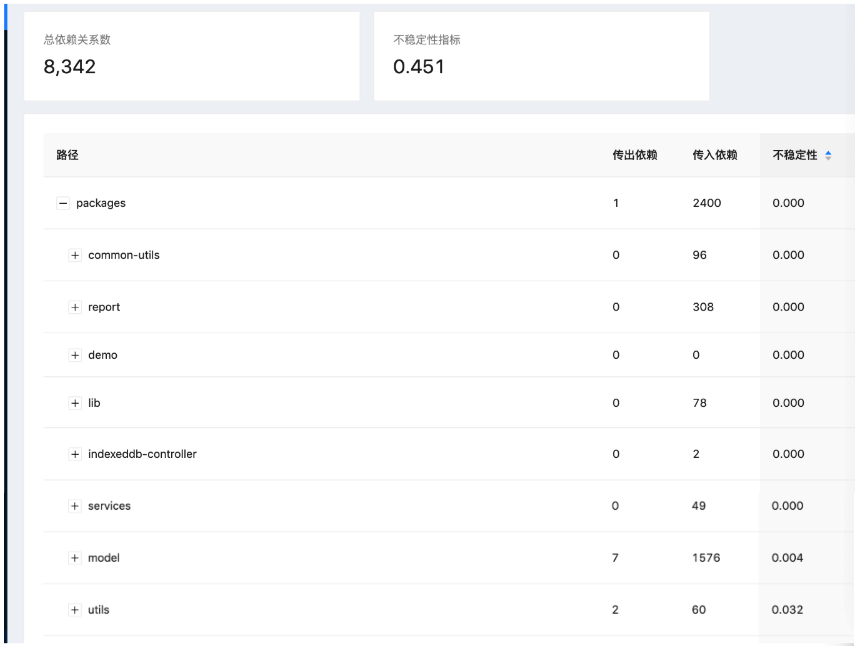
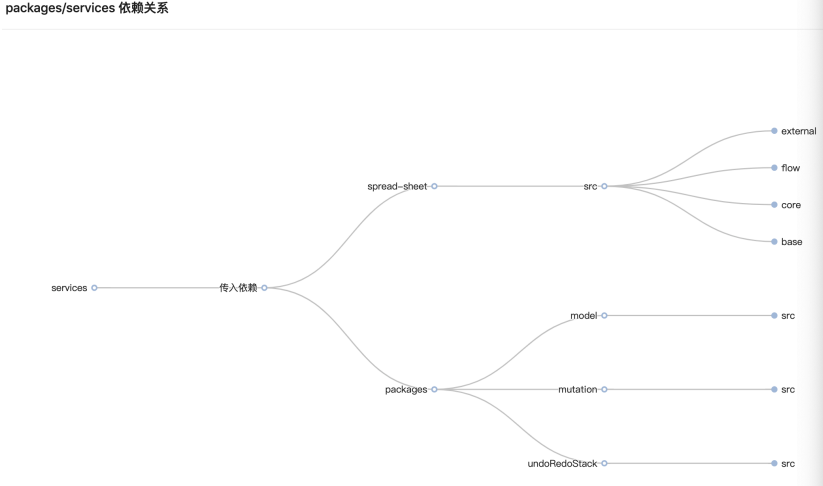
1、依赖关系分析
通过分析import的关系⽣成模块之间的依赖环,辅助开发同学判断模块之间的依赖关系是否合理, 但⽬前项⽬中还有⼀些全局对象没有清理完, 可能会导致依赖关系失真。
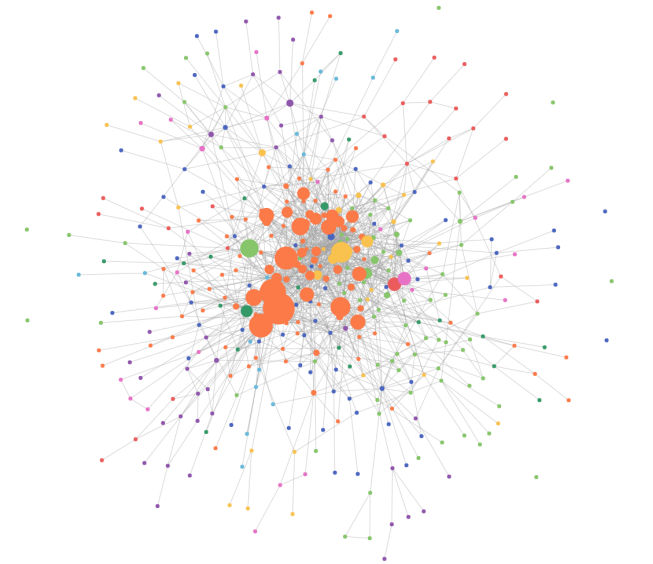
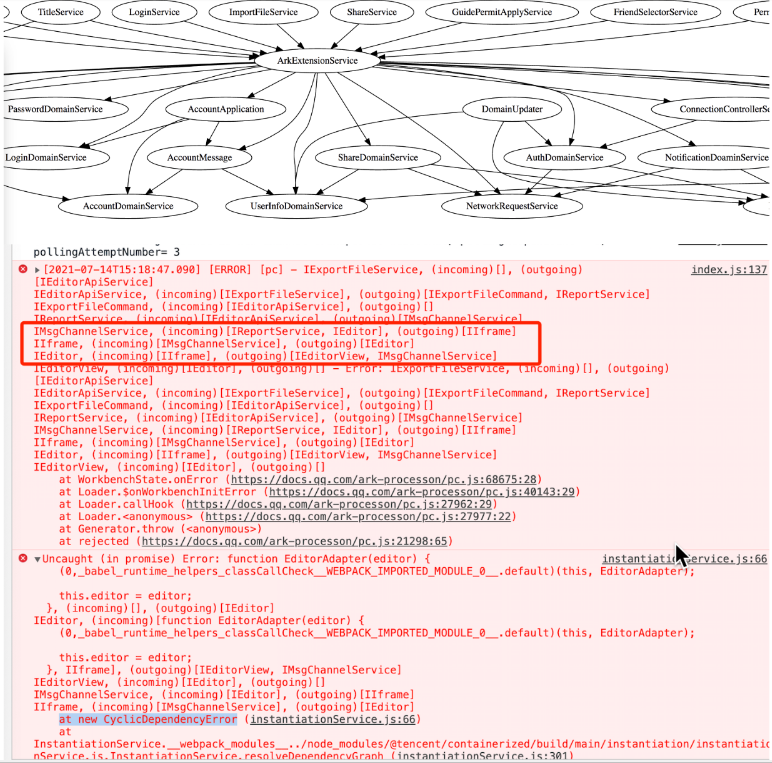
2、循环依赖校验
当依赖注⼊容器内的模块产⽣了循环依赖时会抛出异常
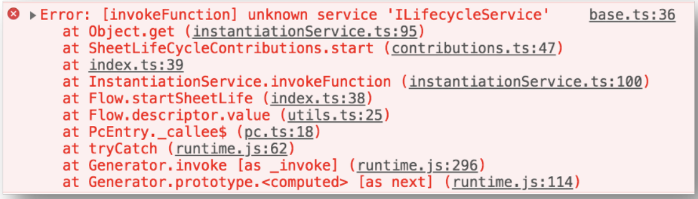
3、分层校验
当容器内的模块调⽤违反了单向依赖原则时,便会抛出异常
4、销毁泄露校验
当⼀个处于销毁树的模块没有正确实现销毁⽅法,便会抛出异常
