腾讯⽂档前端架构思考和实践(⼀) - 模块依赖关系梳理
业务复杂度和开发效率、性能总是成反比的。腾讯文档在需求快迭代的同时,因为代码量大、模块耦合严重,也出现了不少可维护性方面问题。
每个品类都有上千个模块和上万个class,在线文档又天然是一个大的单页面应用,功能与功能之间天然存在很大的耦合性。
举个常见的耦合场景,当用户在表格里插入一行数据时,这一行下面的所有元素都会随之被影响,比如我们必须重算排序、筛选、重新拆分和合并单元格,重新处理被影响的所有函数计算等等。
因为业务的特殊性,这些模块天然就是被耦合在⼀起的,也⾃然⽆法⽤微服务等⽅式去隔离或减轻模块与模块之间的影响。这就意味着,如果我们不想办法好好去管理模块与模块之间的依赖关系,后⾯需求开发效率和代码维护性将变成灾难,改动⼀个模块很有可能会引起其他模块的bug。
⽂档的历史技术债务也说明了这⼀点,在腾讯⽂档初期快速开发迭代阶段,所有模块都是挂在全局对象上,被其他模块直接调⽤。如sheet就有个很⼤的spreadSheetApp全局对象,⽹络层、数据层、渲染层、离线层、feature等所有⼤模块都是直接挂在这个全局对象下的, 并且允许他们互相随意访问。 因为这些历史原因,导致业务中出现了错综复杂的依赖关系,甚⾄包含了不少循环依赖。⽐如最主要的⼏块,编辑器(包括数据层和渲染层)、组件、基础设施、服务等模块都可以互相调⽤。
假设我们在管理⼀个团队,当团队只有5个⼈的时候,管理者可以很清楚的明⽩每个同学负责的职责。这5个同学也可以互相帮忙来完成⼀些别⼈的⼯作。但如果团队扩张到100⼈、500⼈,如果还置之不理,团队⼀定会进⼊混乱状态。我们需要让每个同学有更清晰的职责,并且减少互相之间的依赖。
同样,在代码中,最关键的是模块、class、函数的数量也随着极速膨胀。模块、class间的依赖关系会变得越来越混乱。如果不能正确处理好⼏千个class之间依赖关系,这个项⽬将很快变成⼤泥球。 在这种项⽬⾥开发代码⼀定是很痛苦的,开发速度会急剧下降,bug数也会越来越多。
虽然团队每个同学都能很明确能答出耦合性强的坏处,但从实际开发来看,也许还不够真正重视耦合性强给系统带来的灾难。团队很多前端开发同学⾃从业以来,⼀直在从事⽉抛型⼩⻚⾯的开发,可能对耦合带来的痛苦没有太感同身受。
对于腾讯⽂档这种量级的业务⽽⾔,⼀旦模块变多,系统的耦合性和复杂度也会随之呈指数型增⻓。耦合性带来的坏处主要体现在系统的迭代升级阶段,当需求增加或者变化时:
模块的独⽴性变差,修改⼀个模块有可能影响另外⼀些模块。 因为两个模块是互相依赖耦合的,其中⼀个模块报错,或者并没有报错,⽽是修改了⾃身的接⼝,依赖它的另⼀个模块也可能出现问题。当模块互相耦合之后,我们每修改⼀个模块都被迫变得⾮常⼩⼼。
模块的复⽤性变差。 每当我们想复⽤某 个模块时,因为它紧紧拖着另 些模块,所以这时候必须把另⼀些模块的代码也拷⻉过来。这些额外的模块可能对我们这次需要的功能没有帮助,但还是要始终⼩⼼地保证它们不出问题。⽐如将⼀些代码挪到node中运⾏的时候,如果它们依赖了⼀些浏览器下才能运⾏的模块,开发者还需要反复去mock掉这些模块。
模块依赖关系重构实践:
上⾯从系统⻆度,介绍了分层架构和单向依赖架构带来的⼀些好处。为了让整个系统松耦合易迭代,除了遵守⼤的单向依赖分层原则之外,在⼀些模块内部,也需要让它们保持合理的依赖关系。腾讯⽂档这2年做了不少模块的重构,从⼀开始不关⼼依赖关系,到现在重要模块的开发前必须要求画好uml图且通过评审,部分团队同学在学习进步的过程中也逐渐明⽩了依赖关系合理的重要性。
什么样的依赖关系才是合理的,这个问题是没有标准答案的。⾸先我们要明⽩,系统中总会出现各种各样的依赖关系,⼀些模块总要调⽤另外⼀些模块,那这些模块就会和其他模块产⽣依赖,有些依赖关系是光明正⼤的。
单⼀职责原则指导我们将模块和类拆的更细,每个模块和类不应该负责太多职责。但模块和类数量变多之后,模块和类之间的联系必然也会随之增多。模块和类究竟要保持什么样的粒度,模块和类之间的通信⽅式如何才能更合理?
虽然没有标准答案,但我们可以想想,平时做架构设计的⽬的究竟是什么?如果需求永远不会变化,那么所有的架构设计都是没有必要的。不管代码有多乱,毕竟只要功能可以运⾏,线上没有bug就可以了。就像⼀个再也不会去住的房⼦,我们⾃然也不会关⼼房⼦⾥⾯的旧家具摆的有多凌乱.
进⾏架构设计的唯⼀⽬的是: 当需求变化来临时,我们希望付出尽可能⼩的代价就能满⾜这些需求的变化。
⽽模块之间依赖关系的合理性,就是决定这些代价⼤⼩的最重要因素。
这⾥⽤3个简单例⼦,也是实际业务中遇到的⼀些真实场景,来⼀起讨论什么样的依赖关系是合理的。
1. 登录模块
这个例⼦我在另外⼀篇⽂章⾥曾经提过,现在看起来还是⽐较具有代表意义。 这个例⼦⾥的问题,主要是因为模块的职责划分不明确,导致依赖关系也不可能完全合理,当需求变化来临时,对现有系统稳定性的冲击很⼤,我们被迫对现有代码进⾏⼤量修改。
现在系统⾥有3个组件,分别是登陆组件、⼯具栏组件和sheetbar组件。在没有点击登陆组件完成登陆之前,⼯具栏和sheetbar都是灰显不能点击的。当顺利登陆之后,⼯具栏和sheetbar就会进⼊编辑态,变得可以点击。

这个常⻅的需求涉及到两组模块,第⼀组是⼯具栏模块和sheetbar模块,第⼆组是登录模块。登录模块负责获取或者注销登录态,然后登录态会影响⼯具栏和sheetbar等模块的展示。当登录模块完成登录或者注销登录态的时候,⼯具栏等模块需要根据登录态的变化来完成⾃身状态的变化,⽐如注销登录之后,它们改变⾃⼰样式,以及屏蔽掉点击等事件⾏为。 ⼀般来说,我们的做法都是让⼯具栏和sheetbar分别监听来⾃登录模块的事件,当登录模块产⽣新的事件时,⼯具栏和sheetbar都会收到相应通知,并且随之改变⾃身状态:
1 | // toolbar.ts: |
初看似乎没有什么问题,这两段代码也是符合开闭原则的. 当需求变化时,⽐如系统中新增了右键菜单组件、⽬录组件,可以继续让这些新增的组件模块监听来⾃login模块的事件,原有的⼏个组件都不会受到影响, 如:
1 | // menu.ts: |
我们继续思考⼀下,刚才我们想象了⼀些在未来需求的变更场景,系统中可能新增⼀些其他依赖login的组件模块。但除了这些场景,还有没有可能出现其他需求变更场景,以我们⽬前的设计是没有办法在这些需求变更发⽣时,需要去违反开放-封闭原则的。
在这⾥⼯具栏、sheetbar、右键菜单都依赖了登录组件,登录组件在这⾥成为了其他组件的必需依赖,这种依赖是合理的吗? 当这两种情况发⽣时,这⾥的代码就必然会违反开发-封闭原则:
当系统⾥需要去掉登录组件时,⽐如业务运⾏在⼩程序或者native-app⾥时,登录态都有可能由其他地⽅提供。在进⾏⾃动化测试的时候,我也不希望⼀定要加载登陆组件才能对⼯具栏和sheetbar进⾏⾃动化测试
当登陆组件的login.event.change接⼝发⽣改变时,不管是接⼝名,还是接⼝⾥的参数发⽣改变,其他依赖它的组件⾥内部代码都需要随之进⾏修改
这⾥问题的关键,在于我们没有考虑清楚⼯具栏,sheetbar,右键菜单跟登陆组件之间的联系,它们不应该是互相依赖的关系,⼯具栏,sheetbar,右键菜单跟登陆组件,应该是平⾏且没有关系的组件。在没有登陆组件的环境下, ⼯具栏,sheetbar,右键菜单应该可以继续完成⾃⼰的职责。
再仔细想想,⼯具栏,sheetbar,右键菜单这些组件依赖的并⾮登录这个UI组件,它们实际上依赖的是⽂档的权限状态,我们更好的做法是引⼊权限模块,让其他需要根据权限变更发⽣变化的组件,去依赖权限模块。
由本来的依赖:
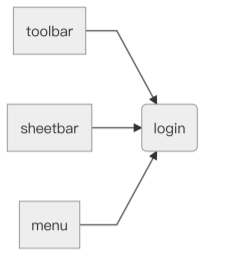
变成
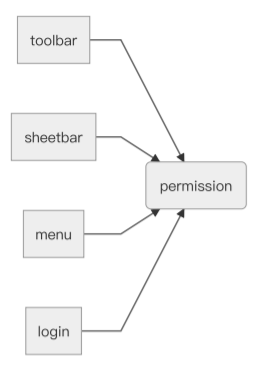
伪代码:
1 | menu.ts: |
当登录成功时: login.ts:
1 | permission.set({ |
这样⼀来,系统中这⼏个模块的耦合性就降低了很多。permission模块相⽐login模块发⽣改变的⼏率要⼩⼀些,不管登录态是由现在的login模块,还是将来由其他模块来提供,permission模块都是可以保持不变的,相对来说permission是更稳定的模块。我们去掉login组件,然后给permission模块⼀些默认的初始值,toolbar,sheetbar,menu就可以在没有login的环境下运⾏。
更适合的依赖
刚才我们在系统中引⼊了permission模块,然后将toolbar,sheetbar,menu对login组件的依赖,转移给了对permission模块的依赖,系统的稳定性得到可增加。
但这个⽅案依然是有缺陷的,permission虽然相⽐login组件更稳定,但它依然不是⼀个⾮常稳定的模块。
拿腾讯⽂档sheet举例,sheet中有很多种权限状态,⽐如⽂档权限,sheet权限,区域权限,⾼级权限等。也就是说permission变化的概率还是经常存在的,⼀开始sheet只有⽂档权限,后来在需求变更过程中才增加了sheet权限、区域权限、⾼级权限、以后还可能增加更多各种各样的权限,当permission变化的时候,依赖permission的toolbar,sheetbar,menu也可能受到影响。
我们再想想,toolbar,sheetbar,menu的状态改变的原因,真的是因为⻚⾯的权限发⽣了变化吗?
作为toolbar,sheetbar,menu这些上层业务的开发者看来,他们其实并不关⼼⻚⾯⾥有多少种权限,也不关⼼当前⻚⾯处在哪些权限,他们只关⼼当前⻚⾯到底是处在只读态还是可编辑状态,如果是只读态,那就让这些按钮灰显和不可点击,如果是可编辑态,那就让这些按钮变得可以点击。
对于toolbar,sheetbar,menu这些上层业务的开发者,这些组件和只读-可编辑态之间的关系永远是稳定的,不管业务中将来会存在多少种权限,⽂档都只有两种状态,要么是只读状态,要么是可编辑状态。⾄于只读-可编辑态和这些权限之间的映射关系到底是怎样,那是别⼈应该关⼼的事情。
所以,我们应该再新增⼀个⽂档状态模块,⽂档状态模块⽤来表示当前⻚⾯是属于只读,还是属于可编辑态。⽂档状态模块是⾮常稳定的,它永远只有只读和可编辑两种状态,不会随着其他组件的增删,或者权限策略的修改⽽发⽣改变。
当权限发⽣改变时,权限模块要去修改⽂档状态模块。我们让toolbar,sheetbar,menu去依赖⽂档状态模块,不再和login组件以及permission模块发⽣联系,toolbar,sheetbar,menu也就变成了更稳定的模块。
整个流程最终变成:
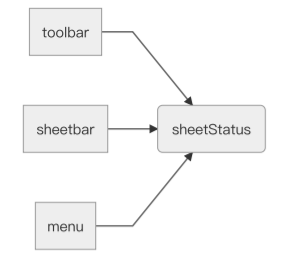
和

最后回顾下刚才的例⼦, 在最开始的时候,toolbar,sheetbar,menu这些组件依赖了不稳定的login组件,使得这些组件本身也变得不稳定,⽽login组件也承担了它本不应该承担的⼀些职责。
接下来,基于这些组件真正的依赖关系,我们分别引⼊了sheetstatus和permission这两个新的模块,其中sheetstatus是⼀个⾮常稳定的模块,toolbar,sheetbar,menu依赖sheetstatus这个稳定的模块,就不再担⼼因为其他事情的变更导致⾃⼰变得不稳定。我们将模块和模块之间的依赖关系转移给了更加稳定的模块,整个系统也就变得更稳定。通过这个例⼦我们明⽩,当系统因为依赖关系混乱⽽变得不稳定,有可能⼀开始我们模块职责的划分就是不合理的。在未来需求发⽣变化的时候,我们就需要花费很多⼒⽓才能让系统适应新的需求。
所以,我们为模块设计职责之前,就需要提前去想象和预估,需求以后有可能会怎么变化,当需求变化的时候,我们要付出多少代价?
第2个例⼦:mutation和model的关系
mutation和model都是腾讯⽂档最重要的模块之⼀。
mutation指的是⽤户的操作指令集经过转换后的原⼦操作。⽐如插⼊⾏列,合并单元格,筛选这些⽤户的操作⾏为,最终都会转化为⼀组包含⽤户⾏为数据的mutation。
model则装载了整个腾讯⽂档数据层的数据结构,sheet、doc、slide都会有⾃⼰的model,在sheet⾥,model主要是由⼀个⼆维数组组成的,⼆维数组⾥的每个元素都和表格上的每个单元格⼀⼀对应。
当我们在腾讯⽂档编辑器⾥输⼊⼀些数据,或者经过⼀些⾏列操作,这些⽤户⾏为经过⼀系列处理后,会最终变成⼀个⼀个的mutation原⼦操作,当这些原⼦操作被运算出来后,就会被转交给model、⽹络层、离线层和渲染层,来分别对后⾯这4个模块进⾏更新,在这⾥我们暂且只讨论mutation对model的更新过程。
进⾏⾏列操作后改变model的伪代码:
1 | // InsertDimensionMutation.ts |
从这段伪代码可以看出,mutation和model之间的依赖关系是很明确的,程序会在InsertDimensionMutation⾥去改变model,InsertDimensionMutation依赖model,这似乎是⼀种看起来很正常的依赖关系。
现在我们再来考虑下,当需求发⽣变更的时候,这些代码是否会受到破坏性的冲击。
第⼀个需求变更场景:
由于各种原因,在线⽂档的model是经常会升级的。⾕歌⽂档的model⾄少已经升级了7次,腾讯⽂档也正处第3次升级中,每次升级都是⼀个痛苦的⼯程,现⽹很⻓时间内都会同时存在两份以上的数据结构。假设我们的mutation和model是耦合在⼀起的,在model升级的过程中,我们就可能得在mutation⾥写上⼀些if、else条件分⽀,来决定mutation到底应该修改哪个版本的model。
1 | class InsertDimensionMutation { |
也就是说,因为model的升级,我们可能被迫要在mutation⾥加上⼀些兼容代码。
⽽mutation是⾮常核⼼和稳定的模块,数据升级是⼀种⽐较随机偶然的⾏为,当这些偶然⾏为发⽣时,我们不希望去修改这些本应该保持稳定的模块。
第⼆个需求变更场景:
mutation的概念最早是⽤在腾讯⽂档sheet⾥,后来我们开发了智能表项⽬,我们发现智能表的mutation和sheet的mutation在很多时候是有可能可以复⽤的。⽐如修改格式,插⼊⾏列等这些mutation。
但是智能表的model却和sheet的model相差很⼤,分歧⼤到不可能对这两个model进⾏共同抽象。⼀旦我们的mutation耦合了sheet的model,那就说明这些mutation⽆法再提供给智能表使⽤了。
第三个需求变更场景:
腾讯⽂档有很多品类,虽然每个品类进⾏协同冲突处理的细节可能有些分歧,但总体⽽⾔,⽆论是sheet,doc,还是slide,从⽤户输⼊数据开始,到完成协同冲突处理的流程都是⼀致的,我们甚⾄可以先⽤⼀套模版⽅法来描述这个流程,然后由各个品类分别提供⾃⼰的mutation、model、view等模块,来组合成某个品类的整体协同冲突处理,各品类协同冲突处理的流程可以套⽤⼀个标准的模版⽅法设计模式。
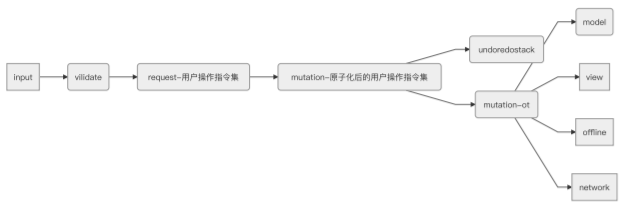
但如果mutation已经和sheet的model耦合在⼀起,那说明其他品类没有可能再重复使⽤这个模版⽅法了,都必须各⾃去建⽴冲突处理整套流程。
根据上⾯列举的⼏个场景可以猜到,如果mutation和model耦合在⼀起,那么当未来的很多需求场景变更时,⽬前的代码是⽆法顺利进⾏扩展的,必须进⾏破坏性的修改。
所以,我们需要让mutation和model分开,⽽不是耦合在⼀起。
⽅法其实很简单,我们为每个品类都新建⼀个apply类,apply类作为胶⽔层,专⻔处理这个品类内⾥mutation和model之间的关系。mutation和model不再需要知道对⽅的存在,它们的联系由apply来完成,mutation和model变得都可以独⽴使⽤。
伪代码:
1 | // sheet |
第三个例⼦:梳理编辑器、⽹络层、连接层和FC组件的依赖关系
这个例⼦稍微复杂⼀点,参与的模块也⽐之前稍微多⼀些。 前两个⽉我在做⼀个需求时,发现项⽬中⼀些地⽅的代码怎么改也改不顺,整理后发现是模块之间的依赖关系不太合适。
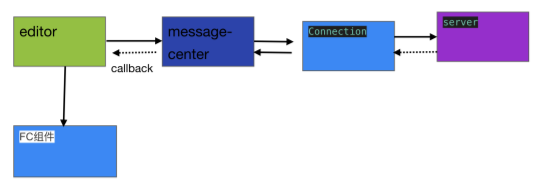
这个需求主要描述前端向后台server提交⽤户编辑产⽣的数据,以及前端监听来⾃后台的数据这两个双向通信过程。整个需求可以⼤致简化为以下步骤:
从前端到后台server:
- ⽤户在编辑器⾥进⾏操作,⽣成⽤户⾏为相关数据。
- 在编辑器模块创建⼀个协同层对象,并将刚刚⽣成的数据提交给协同层。
- 协同层对数据层进⾏冲突处理操作,并通过socket连接将处理后的数据发送给server。
从后台server到前端:
- 协同层监听来⾃server的socket消息(如权限变更)。
- 编辑器监听来⾃协同层的信息(如权限变更)。
- 编辑器将权限变更信息通知权限组件(腾讯⽂档FC组件)。
- 权限组件拿到权限变更信息之后更新⾃身状态。
在不考虑需求变更的场景的前提下,我们先看看当前模块的依赖关系是不是合理的,如果不合理,这些不合理的依赖关系有可能导致哪些问题?
从编辑器到server:
第⼀步: 编辑器创建协同层对象,并将⽤户提交的数据提交给协同层。 编辑器依赖协同层,
这⼀步暂时看来是没有太多问题的。第⼆步:协同层对⽤户提交数据做完协同冲突处理之后,通过socket将处理后的数据提交给连
接层 协同层跟server建⽴连接,看起来好像也没太⼤问题。
接下来我们看看从server到编辑器:
第⼀步: 协同层监听来⾃server的socket消息(如权限变更) 这⼀步看起来不是很正常,原因是模块的职责划分不准确。在实际业务中,权限变更消息是不需要和其他消息进⾏协同冲突处理的,那么server发送权限变更消息给编辑器要为什么⼀定要经过协同层呢?实际上,消息必须经过协同层的原因是,在我们最开始的设计中,socket和后台连接的通道和动作都被设计包含在了协同层当中。 实际上我们更希望socket连接能够独⽴于协同层存在,在腾讯⽂档业务中,除了协同冲突处理之外,还有另外⼀些模块也需要和后台建⽴socket连接,⽐如协作者列表更新、红点通知等等。当socket被包含在协同层⾥⾯之后,权限变更、协作者列表更新、红点通知这些能⼒就不得不去依赖整个协同层。
让权限变更、协作者列表更新、红点通知这些模块依赖整个协同层显然是不必要的,我们需要将socket和server连接的通道和过程都提取出来, 更好的办法是,创建⼀个新的“连接层“模块来放置这些代码。
第⼆步: 编辑器监听来⾃协同层的消息(如权限变更),并将这些消息发送给权限变更FC组件,通知权限变更组件更新⾃身的状态。 这⼀步的问题就更⼤了,⼀⽅⾯,需要权限消息的实际上是FC组件,⽽不是编辑器。从上⾯流程图可以看到,协同层是在编辑器⾥⾯被创建的出来的,并没有机会独⽴暴露接⼝给外界使⽤,编辑器只好在这⾥承担⼀个中转的作⽤,拿到权限消息再通知FC组件。 这就导致了编辑器和权限组件耦合在⼀起,当编辑器不需要权限组件的时候,⽐如将编辑器当作SDK提供给第三⽅使⽤的时候,因为编辑器紧紧耦合着权限组件,导致我们没法复⽤这⾥的代码。 更好的⽅案是,让权限组件仅依赖连接层就可以了。
于是我们改进⼀下,重新画好流程图:
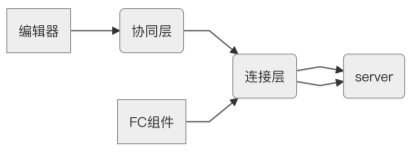
⽬前系统的依赖关系已经得到了⼀些优化,我们将socket连接层从协同层⾥拆出来,分别提供给协同层和FC组件使⽤,⼀⽅⾯,FC组件不⽤再依赖它不需要的协同层。另⼀⽅⾯:FC组件也和编辑器解藕开来,它们在将来都更容易被单独复⽤在其他地⽅。
但⽬前这个模块依然存在⼀些问题,我们分析下连接层的职责,顾名思义,它主要是负责和server建⽴socket连接,并将消息推送给编辑器或者权限组件这些client,为了保证连接层的⾼复⽤性,它本身是不负责承担任何业务逻辑的。
编辑器需要通过连接层传送经过协同冲突处理后的消息,我们也很容易理解,连接层是不可能去承担协同冲突处理这些业务逻辑的。
同理,连接层也不应该去承担协作者(⽐如对协作者列表的展示进⾏节流计算等等)、权限、红点这些业务模块相关逻辑。但这些逻辑⼜是⽐较通⽤的,分别可能被多个FC组件使⽤,也不适合直接放某个具体的FC组件⾥⾯。
所以,更合适的处理⽅式是,我们要在FC组件和连接层中间,新增⼀个业务服务模块,如协作者服务、权限服务、红点服务等等,FC组件只关⼼来⾃这些服务的消息,不再和连接层产⽣关联,保证连接层在任何时候都⾜够通⽤。
我们将这些新增的服务放在application-service⾥,流程图变成:
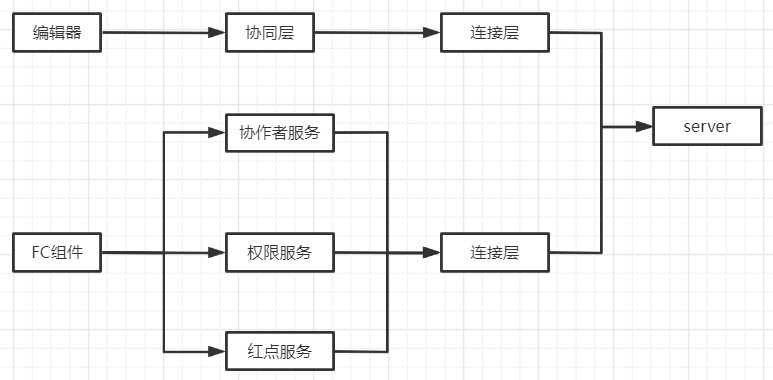
现在再观察下这两个流程图,发现还有点⼩问题,上⾏和下⾏两个步骤都分别新建了⼀个连接层,如果组件多起来,可能⻚⾯中会存在更多的连接层,在线⽂档⽤户喜欢同时打开很多个tab,且⻓时间不关闭这些tab,这些因素加起来,会导致同⼀个⽤户对后台建⽴多次socket连接,对前端和后台都是不⼩的压⼒。
我们最好是在同个⻚⾯中,保证⽤户使⽤的连接层是同⼀个。解决⽅案也很简单,将连接层的创建放到单例⼯⼚⾥,其他消费者都只允许通过这个单例⼯⼚来创建连接层。
流程图变成:
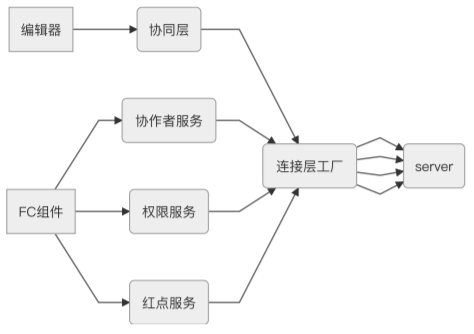
到这⾥,这个例⼦基本就结束了,我们通过⼀系列⽅法,让系统中各个模块的职责变得更清晰,模块之间不产⽣不应该的依赖,增强模块的独⽴性和可复⽤性。
在实际代码cr中,还发现了这些模块之间存在的⼀些⼩问题,主要是两个:
- 不知道是出于什么历史原因,有个⼀些跟version相关的字段被⽹络层和协同层所共⽤,代
码⾥的写法是⽹络层和协同层互相找对象来要这些version相关字段,导致⽹络层和协同层之间
产⽣了循环依赖。
- 解决⽅案是将version这些字段从⽹络层和协同层中提取出来,封装成version模块,让⽹络层和协同层分别依赖version模块,在破除⽹络层和协同层之间的循环依赖之后,整个系统也遵循了单向依赖原则。
- 连接层需要的参数⾮常多,导致创建连接层的过程对于业务开发者来说⽐较麻烦。
- 解决⽅案是给开发者提供⼀个builder来辅助创建连接层对象
总结:
我们刚刚花了不⼩的篇幅,通过三个实际业务开发中遇到的场景,来介绍如何⽤更好的⽅式来划分模块,以及设置模块之间的依赖关系。
这两年在业务需求间隙中,也陆续对数据层、渲染层、⽹络层、连接层、离线层、编辑器&插件、Workbench、数据领域服务、database等核⼼模块的依赖关系进⾏了⼀些梳理&重构,依照它们的职责、复⽤度、可替换性等等,去重新划分模块和设置模块之间的依赖关系。
虽然这些模块的构成和作⽤都可能相差很⼤,但对它们依赖关系的设置,可以总结出⼀些规
律:
- 将抽象⽽稳定的代码放在系统⾼层
- 将具体⽽不稳定的的代码放在系统低层
- 复⽤性越强的模块放在系统⾼层,反之,不太需要复⽤的模块放在系统低层
- 根据业务模块加载优先级,对性能要求越⾼的模块放在系统⾼层
总⽽⾔之,当我们在设计⼀些模块时,需要不停去思考,这⾥的业务需求在将来有可能会如何发⽣变化?当这些变化来临时,这些模块是需要被修改、被替换还是被删除?我们付出的代价是否⾜够⼩?