腾讯⽂档前端架构思考和实践(⼆) - 单向依赖架构
从代码可维护性的⻆度来看,相⽐模块内部的可维护性,模块与模块之间的耦合关系清晰要更加重要。
毕竟模块内部的实现再糟糕,影响的也只是模块内部⾃身,如果这些模块提供了可⽤性⾼的对外接⼝,⾄少在外部看来,它们还是⼀些好模块。但如果模块与模块的联系混乱不合理,则会影响整个系统的健壮性。
我们希望借鉴⼀些松散低耦合的架构模式来帮忙完成模块与模块之间的连接。常⽤和合适的架构模式在《架构整洁之道》这本书中都有答案,⽐如领域驱动架构、洋葱架构、六边形架构等。这⾥不详细介绍这些架构模式。我们要知道的是,⽆论是哪种架构模式,都需要遵循⼀个最重要的原则 - 单向依赖原则。
随着系统的迭代,当开发者需要修改代码时,他们更⼤概率需要去修改那些接近产品需求、具体和不稳定的代码。所以,我们希望将远离产品需求、抽象⽽稳定的代码放在系统的⾼层(内层),将接近产品需求、具体和不稳定的代码放在系统低层(外层)。就像⽤积⽊搭建房⼦时,我们需要把最坚固的积⽊搭在下⾯。
看下⾯这个图:

假设系统中被分为了A、B、C、D这4层,那么A是相对的最内层,外层依次是B、C、D。如果最内层的A模块被修改,则依赖A模块的B、C、D模块都会分别受到牵连。在静态类型语⾔中,这些模块因为A模块的改动都要重新进⾏编译,⽽如果它们引⽤了A模块的某个变量或者调⽤了A模块中的某个⽅法,那么它们很可能因为A模块的修改⽽需要随之修改。所以我们希望A模块是最稳定的,它最好永远不要发⽣修改。
但如果外层的模块被修改呢?⽐如D模块被修改之后,因为它处在最外层,没有其他模块依赖它,它影响的仅仅是⾃⼰⽽已,A、B、C模块都不需要担⼼它们收到任何影响,所以,当外层模块被修改时,对系统产⽣的破坏性相对是⽐较⼩的。 如果从⼀开始就把容易变化,经常跟着产品需求变更的模块放在靠近内层,那意味着我们经常会因为这些模块的改动,不得不去跟着调整或者测试系统中依赖它的其他模块。
在⼀个严格单向依赖的系统中,依赖关系总是只能从外层指向内层,这样才能得到⼀个更稳定的系统。
再看⼀个具体的例⼦:
假设我们要写⼀个⾮常简单的需求, 虽然这种代码不太可能在现实中出现:
⻚⾯中有⼀个input输⼊框,当⽤户输⼊⼀些⽂字后,会定时将这些⽂字通过⽹络请求发给后台。同时input输⼊框会和后台保持⼀个http连接,当后台数据产⽣变更的时候,这些数据将通过http请求推送给前端,以便通知前端来更新UI。
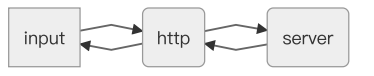
代码也许会这样写:
UI模块:
1 | // input.ts: |
1 | // httpRequest.ts: |
从这两段伪代码很容易看到,input 和 httpRequest 这两个是互相耦合在⼀起的。⽆论是 input 还是 httpRequest ,⼀旦修改了它们其中某⼀个模块,另外⼀个模块也会相应随之受到影响。如果有天 httpRequest 的接⼝变化了,从 send 变成了 xxx,我们需要在 input.ts ⾥修改 input.onclick ⽅法的内部实现,以重新适配 httpRequest 的接⼝。
同样,如果某 天UI相关的input框 发⽣了变化,我们也需要修改 httpRequest.ts 。input 这种UI相关模块其实是更接近产品需求,也就是更容易发⽣变化的低层模块。今天有可能是 input、明天有可能换成下拉框,后天可能⼜要新增⼏个input,再过⼏天甚⾄这些需求都下线了。但因为这些UI模块被耦合 httpRequest.t s⾥,被 httpRequest.onchange ⽅法所依赖。当这些变化经常发⽣时,我们被迫经常去改动 httpRequest模块。
相⽐⽽⾔,httpRequest模块 相对是稳定得多的,需要改动它的时候很少。它是更稳定和通⽤的模块。 所以,我们需要将 httpRequest模块 放在更⾼层的位置,UI可以依赖httpRequest,但反过来httpRequest不能依赖UI。httpRequest相⽐UI更稳定,发⽣改变的机会很少,当不稳定的UI发⽣变化时,因为httpRequest没有依赖UI,httpRequest不会因为UI的变化⽽受到任何影响。
稳定依赖原则 - 模块的依赖关系必须指向更稳定的⽅向
通过上次这个⼩例⼦,我们明⽩了,要向让系统变得更健壮和易修改,模块的依赖关系就必须指向更稳定的⽅向。
将稳定的模块放在⾼层,将不稳定的模块放在低层,让不稳定的模块去依赖稳定的模块。这样⼀来,当不稳定的模块发⽣变化时,不会影响那些稳定的⾼层模块。

如上图,当模块C被改动时,不会影响模块A和模块B,只会影响模块D,我们只需要确认模块D能适应模块C的改动就可以了。
如何分辨稳定和不稳定的模块
当我们得出稳定依赖原则之后,为了帮助我们更好去划分模块的层级,在系统设计开始之前,我们可以⼤致估算出⼀些重要模块的稳定性评级,当然这些稳定性的划分规则不是永恒固定的,有可能随着业务需求或者具体场景的不同⽽发⽣变化,我们可以拿来参考。
最稳定的模块通常是⼀些系统函数或者简单的⼯具类,⽐如系统中的Array、或者utils中的⼀些url、cookie类等等。在我印象中不记得它们api发⽣过变化。其他模块依赖这些⼯具类时基本是很放⼼的,不⽤担⼼它们以后会因为什么奇奇怪怪的原因,导致其他模块挂掉。
其次是系统中⼀些通⽤业务模块,⽐如⽹络层、本地数据库等,虽然它们有可能因为业务逻辑的变迁⽽发⽣⼀些变化 但我们在设计这些通⽤业务模块的时候 ⼀般会尽量保证它们的接⼝是向前兼容的,也会尽量让这些模块以后的维护符合开放-封闭原则。它们也可以被认为是基本稳定的。
再其次是⼀些核⼼业务逻辑,⼀个程序&业务的本质,是⽤不同的数据载体和展示⽅式来表达核⼼业务逻辑。⽐如股票软件中,核⼼业务逻辑是股票的盈利规则,期权的⾏权规则等等,这些规则是很少变化的。在腾讯⽂档⾥,核⼼业务逻辑是对⽤户数据的操作,⽐如协同处理,格式转化,函数计算等。
这些核⼼业务逻辑在某个业务⾥是很少发⽣变化的,上层的业务需求是多变的,但核⼼业务逻辑不应该随着上层业务需求的变化⽽经常变化。它们也可以看成⽐较稳定的模块。但需要额外注意的是,这些核⼼业务逻辑很容易不⼩⼼带⼊不稳定的其他逻辑,导致它们的稳定性变差。
⽐如我们在协同冲突处理逻辑⾥,如果带⼊了不同品类(doc、sheet、slide)的协同冲突处理实现分歧,协同冲突处理就将变成不稳定的模块,因为它耦合了不稳定的“品类”,品类是会随着产品需求膨胀的,当我们新增流程图这个品类时,就可能要去改动协同冲突处理模块。
再⽐如我们在⽤户信息的核⼼业务逻辑⾥,如果带⼊了“微信登陆”和“企业微信登录”账号的分歧,那⽤户信息也将变成不稳定的模块,我们需要写if、else来处理这些分歧,⽽且分歧会随着“qq登陆”、“xx登陆”等账号体系的扩展,变得⽆法收敛。
所以,我们平时要多辨别核⼼业务逻辑与上层业务需求的区别,尽量不要让它们混杂在⼀起。
这三块的稳定程度是 核⼼业务逻辑 < 通⽤业务模块 < ⼯具类,但都可以划分为较稳定层。
接下⾥就是⼀些不稳定的模块。
这些模块通常来说都是⽐较接近产品需求的。⼀个登录的需求分解来看,⾥⾯包含很多不稳定的部分:⽐如登录⽅式,所需参数,登录后的动作等等,这些东⻄本身都是易变的,在不同的项⽬,不同需求,或者不同⻚⾯⾥,可能就存在不同的具体实现。 另外导致它不稳定还有⼀个原因,这些上层产品需求经常发⽣变更,当我们开始设计这些模块时,就要想象在它们经常变更的场景下,这些代码应该如何适应和修改。
最后⼀部分,也是最不稳定的部分,就是程序的UI部分,在许多前端开发者印象中,⼀个需求好像都是由业务逻辑部分 + UI部分组成。但实际上,UI只是核⼼业务逻辑的⼀种细节表达⽅式。除了UI之外,核⼼业务逻辑还可以运⾏在node端,或者以命令的形式运⾏在控制台,或者跑在单元测试⾥。另⼀⽅⾯,UI是最接近产品经理、设计师和⽼板的部分,它们天然就是最不稳定的。 UI还存在很⼤的端扩散性,腾讯⽂档现在⼤概有10来个终端,pc、mobile、⼩程序、app,pc-app,每个终端⼜有tob和toc版本,这些终端的差异,会导致UI也多多少少产⽣差异。
最后,还有⼀些因为宿主不同导致的不稳定性,⽐如在腾讯⽂档app和企业微信app⾥,openurl接⼝的实现可能不⼀样。我们也需要将这些不稳定性,隔离在稳定的模块之外,千万不要在稳定的模块⾥写这样的代码。
1 | if (tencentdocapp) { |
这种情况我们在后⾯有机会再讨论。
让依赖遵循单向依赖原则 刚刚已经分析和整理了⻚⾯中的主要模块,并依照稳定程度给它们分成了不同层级,现在我们可以开始尝试设计⼀个遵循单向依赖原则的系统。让系统中不稳定的模块去依赖更稳定的模块,使得整个系统的依赖关系,总是指向更稳定的⽅向。
从⼤的⽅向,我们将腾讯⽂档前端代码⼤致分成这⼏层:
- 基础设施层
- 服务层
- ⽤户接⼝层
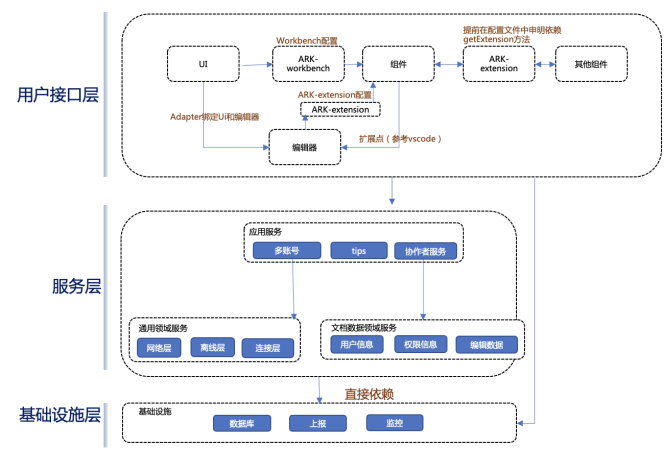
最下⾯的是基础设施层,⾥⾯都是⼀些和业务逻辑&产品需求完全⽆关的基础设施,上⾯的其他模块可以直接依赖他们。
中间是服务层,服务层⼜包括了领域服务和应⽤服务这两块。
领域服务包含⽂档数据领域服务和通⽤领域服务。⽂档数据领域服务是对后台字段的⼀些属性映射,参考领域驱动设计,划分了⼀些实体、服务和聚合。通⽤领域服务则是系统中共各个品类使⽤的⼀些通⽤服务,如⽹络层、离线层、离线层等等。领域服务层和业务逻辑有关,但希望他们尽量原来产品需求,它们也是较稳定,复⽤性较强的⼀层。
领域服务上⾯是应⽤服务层,应⽤服务层相⽐领域服务层,更接近产品需求,⽐如我们的朵账号服务、协作者服务等,它们的内部逻辑并不太稳定,经常随产品需求的变化⽽变化。应⽤服务层和领域服务层的依赖关系是从上到下的。
在⼀些领域服务之间不⽅便直接通信的时候,领域服务也经常被组合成应⽤服务,提供给更上层使⽤。⽐如展示协作者信息的需求,需要连接层模块和⽤户信息模块发⽣⼀些关系。 但连接层和⽤户信息之间是不⽅便直接耦合通信的,因为它们⼀旦耦合在⼀起,连接层和⽤户信息都将变得难以复⽤。所以这时候我们会在应⽤服务⾥建⽴⼀个协作者服务,协作者服务作为连接层和⽤户信息的facade,像可拆卸的钉⼦⼀样,将连接层和⽤户信息暂时钉在⼀起。 最上⾯是⽤户接⼝层,这⼀层主要对接⽤户的输⼊输出,以及UI展示,UI部分,包括⼯具栏、头部栏的绘制等,这⼀层因为更接近产品需求,它们通常也是更不稳定的模块。所以服务层和基础设施层都严禁直接依赖⽤户接⼝层。
⽤户接⼝层其实是⾮常庞⼤的⼀层,编辑器、组件、UI等⼏个⼤模块都处在这⼀层,这⼏个⼤模块虽然处在同⼀层,但它们其实都有很强的独⽴使⽤的必要性,所以它们也不能直接进⾏依赖,需要⽤合适的通信⽅式将它们联系起来。这⾥的依赖关系以及通信⽅式会在后⾯的《插件化架构》中进⾏介绍。
收益举例:多引擎渲染层
举⼀个实际例⼦来说明单向依赖架构的优点。
在腾讯⽂档初期,整个项⽬都是由开源项⽬改造⽽来,当时都还没有引⼊import模块管理,数据层和渲染层的代码⾃然也是耦合在⼀起的。
数据层和渲染层相⽐,数据层的逻辑是要相对更稳定的,⽐如函数计算、协同冲突这些数据层相关核⼼业务逻辑,它们较少因为产品需求的增加⽽发⽣特别⼤规模的更改。除了运⾏在浏览器内,它们也应该可以被独⽴运⾏在服务端、app端、以及⾃动化测试⾥,数据层即使运⾏在不同的环境内,它的逻辑也是具有⼀致性的。
但渲染层的稳定性相对要差很多,渲染层和数据层是多对⼀的关系。数据层我们只需要关⼼⼀份代码就可以了,但渲染层是会随着产品需求的增加⽽膨胀的,⽐如最近两年和未来⼏年,除了最开始的dom渲染层,我们已经或者即将增加canvas、⼩程序、webgl、native等渲染层。在终端上,除了pc-web,后⾯⼜增加了mobile-web、pc-app、mobile-app、ipad等各种各样的渲染层。
很明确的是,数据层绝对不能对渲染层产⽣依赖,如果这样的话,那频繁多变的渲染层,⼀旦有⻛吹草动都会反过来影响数据层的稳定。
基于上⾯的原因,最近2年内,sheet、doc、slide各⼤品类都已经做完了数据层和渲染层的分离。
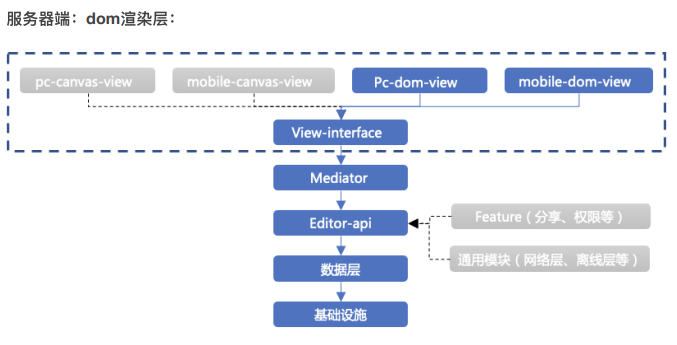
拿sheet举例,数据层和渲染层⼤致的依赖关系如下图:
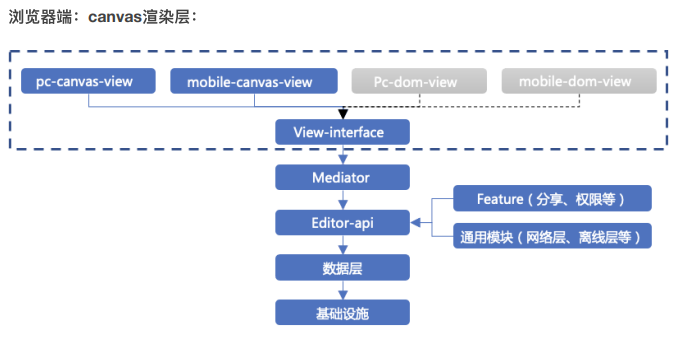
从图⾥可以看到,数据层处在渲染层的⾼层位置,数据层完全不了解渲染层的细节,⾃然数据层也不会因为渲染层的变动受到影响。
当我们实现 sheet-ssr 直出需求时,渲染层因为处在系统的最低层位置,它的变动不会对系统中其他模块产⽣影响,所以这时候,开发者需要关注的事情是⽐较少的,他们只需要在系统最低层,将 canvas 渲染层换成 dom 渲染层就可以了。
因为单向依赖原则带来的优点,在我们开发完⼀个简单的 dom 渲染层之后,很快就让 dom 渲染层融⼊到整个系统中。
总结:
让系统想办法遵守单向依赖原则,对系统的可维护性、可替换性、性能都有⾮常明显的好处。这也是创建⼀个松耦合系统⾮常重要的⼀条原则。
在现实操作中,也经常会存在⼀些这样的场景,模块与模块⽆法百分百的遵照单向原则摆放好,总会有时候似乎⾼层模块不得不去依赖低层模块。
腾讯⽂档的数据层和渲染层依赖关系可能就不得不打破单向依赖原则。前⾯我们已经分析过,数据层是⾼层模块,渲染层是低层模块,正常的情况下应该是让渲染层去单向依赖数据层。
但在实际业务代码中,数据层总会依赖渲染层的选区信息,⽐如合并单元格的数据层相关代码⾥,我们要知道⽤户在渲染层划定了哪些选区范围来进⾏合并单元格动作,这就会造成数据层得依赖渲染层的结果,数据层始终要去渲染层⾥拿到选取信息:
伪代码:
1 | // mergeCellRequest.ts |
但我们希望阻⽌数据层依赖渲染层,也就说数据层不能直接去渲染层获取selection相关信息。
有⼀些简单的办法就可以满⾜我们的需求:
第⼀种办法:
将selection选区信息从view⾥拆出来,MergeCellRequest虽然不能依赖view,但依赖selection选区信息是可以的,selection模块⽐view要轻量很多,让MergeCellRequest依赖selection对程序没有太多负⾯影响, 在⼀些没有view渲染层,需要数据层独⽴运⾏的环境⾥,为数据层提供⼀个selection模块也相对要容易很多。
1 | import selection from 'selection'; |
第⼆种办法更简单⼀些,可以⽤依赖倒置⽅法,让数据层去依赖渲染层的抽象接⼝,抽象接⼝⽐具体的渲染层也要更稳定⼀些。
1 | //定义接⼝ |