背景
痛点一:只要出现文案的国际化处理,必须在文件顶部导入 i18n
痛点二:不能在组件里面直接写中文,必须得用 i18n.t 方法包裹
痛点三:必须得给每一个中文文案想一个变量名
痛点四:必须再从翻译团队给的翻译excel表格里面找到这个中文对应的繁体与英文,然后再一个一个的去替换 zh.json hk.json en.json 中的对应文案
痛点五:翻译团队可能会漏掉部分文案的翻译,必须得再去统计漏掉了那些,然后再次联系翻译团队;
痛点六:产品修改文案时,必须先提 coding,走正常迭代流程,然后研发再去修改,非常简单的需求,却无法快速响应;
目标
目标一:所有需要研发手动更改的地方全部通过自动化处理
目标二:允许研发在编码过程中直接写入中文文案
目标三:使产品可以对文案进行维护和更改,而无需走繁琐的迭代流程
目标四:降低研发与翻译的沟通成本,使翻译团队可以直接对未翻译的文案进行更改
目标五:提高开发效率
解决思路 为了提高开发效率,那么使研发同事直接忽略掉国际化的这个过程肯定是最有效的方法;
要忽略掉国际化的过程,那么使开发同事在代码中直接编写中文肯定是最直接的。
所以 要使研发同事在代码里直接写中文,我们提供工具来实现自动国际化【要给研发同事提供自动进行国际化的工具】
为了使翻译团队与产品可以方便的对文案进行维护,所以需要对项目里的文案进行集中化的管理;
当实现对文案的集中化之后,我们就可以对文案进行增删改查,过滤出没有翻译的文案,方便翻译团队提供翻译;
所以 我们需要一个【后端服务】 进行对文案的集中化管理,需要一个【客户端程序】 方便翻译团队与产品进行维护
功能设计 translate-cli – 给研发同事提供的自动进行国际化的工具 研发同事直接直接在代码里写中文了,不再处理国际化了,那么 所有研发不处理的内容,都转移到了工具身上
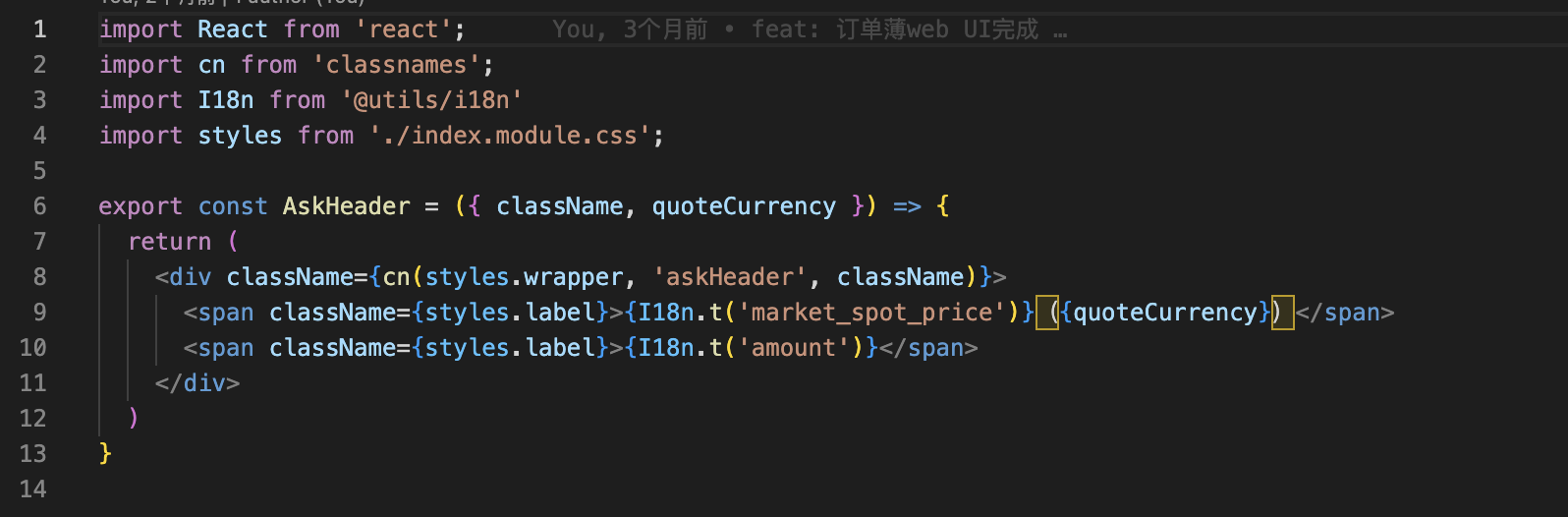
将代码里的中文替换成一个变量名,并用 I18.t 包裹;举个🌰 <span>价格</span> => <span>{I18n.t('price')}</span>
给存在 18n.t 的代码里,导入 i18n ;举个🌰:如果代码里存在 <span>{I18n.t('price')}</span> ,那说明有国际化处理,在文件顶部就需要导入 i18n
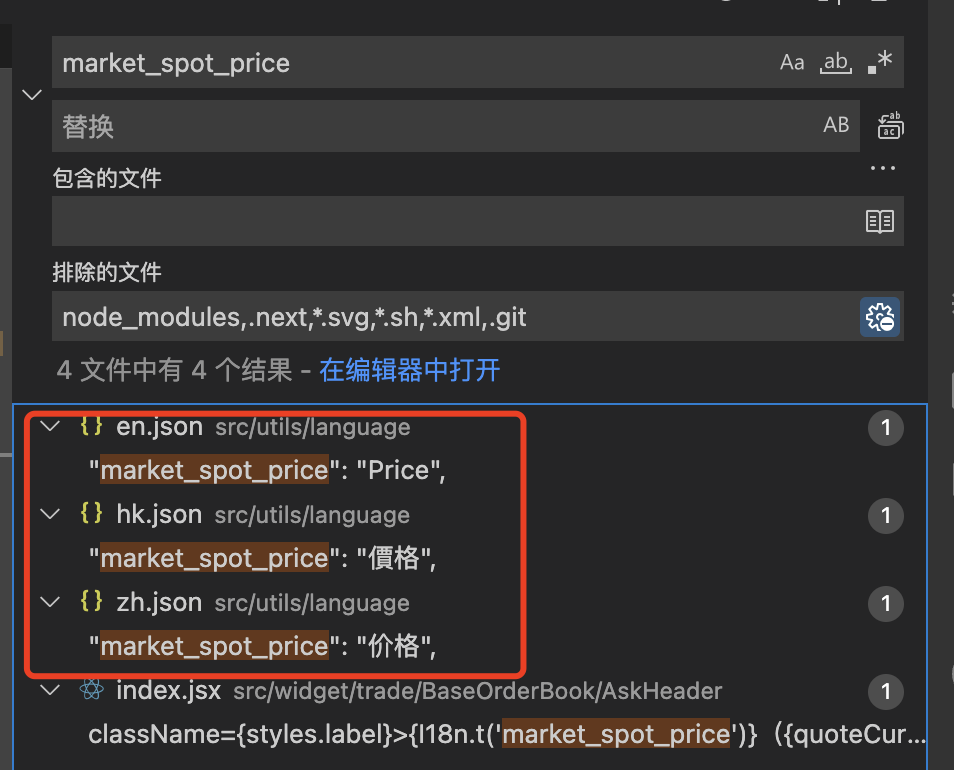
将中英繁对应的文案输出到 zh.json hk.json en.json ;
translate-server – 对文案进行集中化管理的后端服务
将所有项目的文案收集起来
给每一条文案,生成一个变量名;同样的文案,生成同样的变量名
管理文案的翻译
translate-client – 给翻译和产品提供的维护文案的客户端程序
将 translate-server 的数据进行可视化呈现
可以对 translate-server 的数据进行增删改查
【重点功能】找出未翻译的文案,方便翻译团队进行翻译,解决漏翻译问题
【重点功能】批量新增翻译,当开始新的一整块的需求开发时,肯定不能让翻译团队一条文案一条文案的翻译,效率低,体验差,所以需要批量新增
【重点功能】基于批量新增,需要草稿功能,不能输入了半天,结果一个出错,输入的内容没了
【重点功能】查找重复内容,将重复的变量名、中文、英文、繁体找出来,方便修改核对
工具形态
translate-server 后端服务【Node】【Koa2】【Mongodb】
translate-client Web客户端 【Vite】【React】【Typescript】
translate-cli 命令行工具
为什么选择命令行工具形态?项目构建前运行一次对应命令,完成项目内文案替换,使用起来最简单
Translate-Cli 命令行工具 如何用 Node 写命令行 1. 在 package.json 提供 bin 字段
translate 提供的命令index.js 运行 translate 命令时,要执行的文件
2. index.js 内 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #!/usr/bin/env node const { Command } = require ('commander' );const program = new Command ();program.version (require ('./package.json' ).version ); program.command ('scan <main-dir>' , '要扫描的目录' , {executableFile : './bin/scan' }) const distributeTheOrder = (params ) => { if (params?.help ) { program.outputHelp (); process.exit (1 ) } } program.parse (process.argv ); distributeTheOrder (program.opts ())
#!/usr/bin/env node 【必须的】用什么解释器去执行这个脚本commander Nodejs 写命令行的一个简便工具【中文文档】 第4行运行 translate --version输出工具的版本号第14行解析命令行参数第6行定义一个命令 scan是指令,<main-dir>是指令接收的参数,executableFile表示指令执行时,执行那个脚本distributeTheOrder:translate scan会执行 ./bin/scan脚本,但用户可能输入 translate xxx``distributeTheOrder就是处理所所有例外,这里的处理逻辑就是,输出帮助菜单
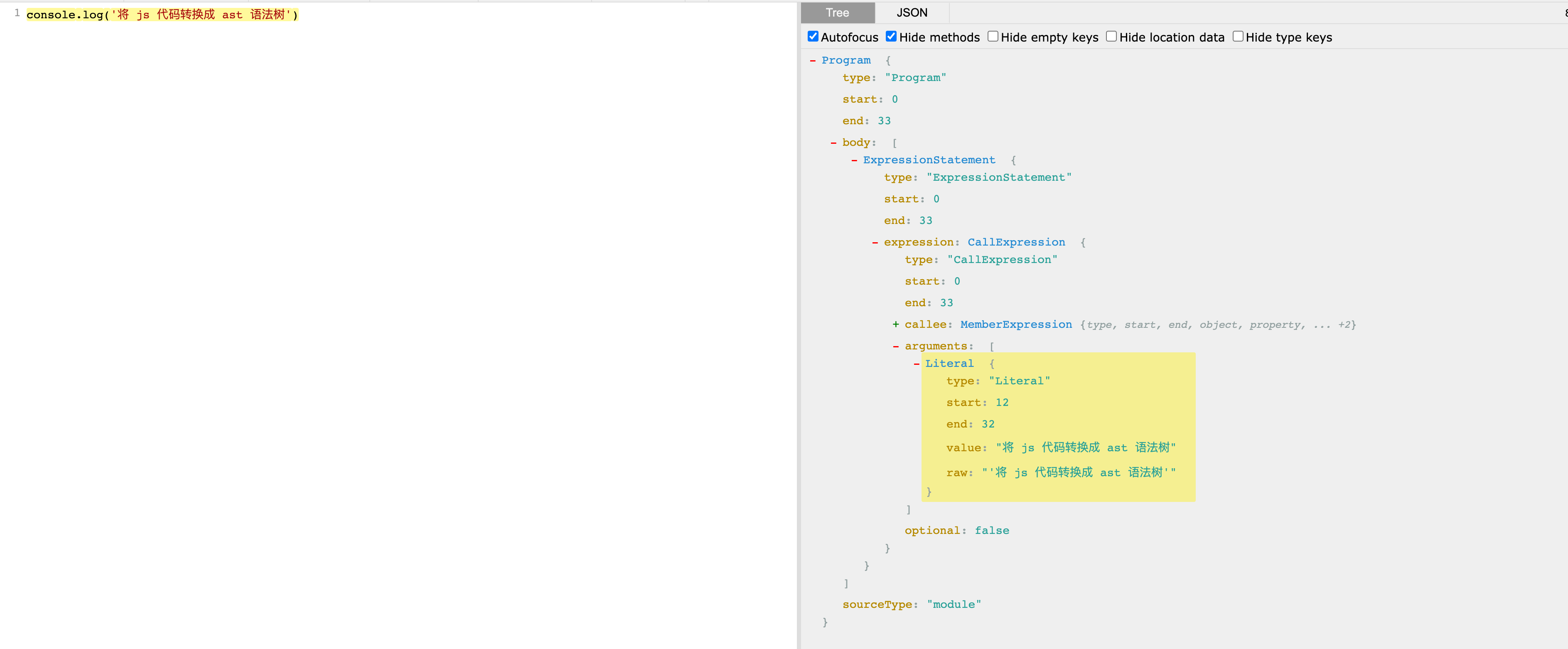
如何找出js代码内的中文 核心思想:AST 语法树
使用工具: **jscodeshift**
文档: https://github.com/facebook/jscodeshift
辅助工具: https://astexplorer.net/
简单🌰 将 js 代码转成 ast 语法树 1 2 3 const j = require ('jscodeshift' )const ast = j (`console.log('将 js 代码转换成 ast 语法树')` )
1. 从 ast 中找到中文 1 2 3 4 5 6 7 8 9 10 const reg = /[\u4e00-\u9fa5]/ const zhNodeAst = ast?.find (j.Literal )?.filter (path => return reg.test (path.value .value ) })
2. 将中文替换成 I18n.t(‘变量名’) 1 2 3 4 zhNodeAst.forEach (path => const content = j (`I18n.t(${这里是生成的变量名} )` ).find (j.ExpressionStatement ).__paths [0 ].value ; j (path).replaceWith (content); })
replaceWith用来替换原有内容,但它接受的参数必须是 ast 语法树,所以我们在 第2行先生成 ast 语法树,然后从里面找出我们要添加的节点,然后在 第3行进行替换
3. 将 ast 还原成代码 我们以上完成了源代码的解析与替换,但是现在还是 ast,我们最后需要的是可以执行的代码,所以我们最后一步需要把 ast 还原成代码
1 2 const code = ast.toSource ()
遍历整个项目文件 基于以上内容,我们完成了整个 ast 代码处理,但是在实际过程中,我们的代码是存在 .js文件内的,而 jscodeshift方法式将字符串解析成 ast 语法树,【所以我们需要读取 js 文件】
使用工具:pang-fs
文档:https://www.npmjs.com/package/pang-fs
1. 读取文件内容 1 2 3 4 5 const pangfs = require ('pangfs' )const j = require ('jscodeshift' )const text = pangfs.readFile ('src/index.js' )const ast = j (text)
2. 递归遍历整个项目 实际上,我们的项目是由一个一个的文件构成的,文件可能存在于各个文件夹下面,文件夹下面还有文件夹,文件还分为 .js .jsx``.css``.svg``.webp等各种文件,而我们所需要处理的只有 **js**和 **jsx**文件 ,所以还需要对文件进行过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 const scanRun = (path ) => { const fileList = pangfs.readDir (path, 'file' ); const dirList = pangfs.readDir (path, 'directory' ); const jsFiles = fileList.filter (fileName =>endsWith ('.js' ) || fileName.endsWith ('.jsx' )) let index = 0 ; while (jsFiles.length && index < jsFiles.length ) { const filePath = `${path} /${jsFiles[index]} ` ; const text = pangfs.readFile (filePath) const ast = j (text) index++ } if (!dirList?.length ) { return } dirList.forEach (dirName => const currPath = `${path} /${dirName} ` this .scanRun (currPath) }) } scanRun (`${pangfs.getCurrPath()} /src` )
获取中文对应的变量名 当我们可以通过递归整个项目,读取 js``jsx 文件内容之后,我们就可以完成 ast 解析,找到没有被翻译的中文,但在这个时候,其实还有一个问题,我们的 web 项目目前是 flow和 js混写的,所以常规的 j(text)对于 flow语法的 js 会报错,所以我们需要用 flow的解析器来解析文件内容
1 j.withParser ('flow' )(text)
flow 的解析器 **flow-parser**必须用 0.144.0 版本,不能用最新版本,最新版本有些语法解析会报错
为了避免 **flow**解析也报错,所以我们最好把 js 能用的解析器都用上,一个解析不过用下一个继续解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #parserCode (text, filePath ) { let ast; if (!ast) { try { ast = j.withParser ('flow' )(text) } catch (error) { throw new Error (`解析失败: \n${filePath} \n${error?.message} ` ) } } if (!ast) { try { ast = j (text) } catch (error) { } } if (!ast) { try { ast = j.withParser ('babel' )(text) } catch (error) { } } if (!ast) { try { ast = j.withParser ('tsx' )(text) } catch (error) { } } return ast }
之后要做的就是从解析出来的 ast 中,找到未翻译的中文,然后调用后端接口,将中文进行上报,获取到中文对应的 key,然后在进行替换。
但是需要思考一个问题,一个文件内肯定有很多未翻译的中文,我们找到一个就上报一次,再替换一次,效率低,性能差
为了解决这个问题,我们需要先将找到的中文暂存起来,替换的方法封装起来,然后将这个文件内的所有未翻译的中文一次性的上报,等到拿到key之后,再进行替换。
找到未翻译的中文 上面我们完成的是,找到所有中文,接下来要做的就是找到没有被 **i18n.t**包裹的中文,同时 **console.log**内的中文也不要
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const zhNodeAst = ast?.find (j.Literal )?.filter (path => return reg.test (path.value .value ) })?.filter (path => const callee = path.parent .value .callee ; if ((callee?.object ?.name ?.toLocaleLowerCase () === 'i18n' && callee?.property ?.name === 't' ) || callee?.object ?.name === 'console' ) { return false } return true })
定义一个 Object ,将未翻译的中文和对中文替换的动作封装进去 Object 结构设计 **{key: Function[]}**
key未翻译的中文value的类型是 function[],之所以是 Array类型,是因为可能存在同样的中文文案,对于每一个文案我们都需要一个替换动作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 const actions = {}; zhNodeAst.forEach (path => const value = path.parent .value ?.type === 'JSXElement' ? path.value .value .trim () : path.value .value ; const action = (path ) => { return (key ) => { if (path.parent .value ?.type === 'JSXAttribute' ) { const content = j (`{${i18nName} .t('${key} ')}` ).find (j.BlockStatement ).__paths [0 ].value ; j (path).replaceWith (content) } else if (path.parent .value ?.type === 'JSXElement' ) { const content = j (`{${i18nName} .t('${key} ')}` ).find (j.BlockStatement ).__paths [0 ].value ; j (path).replaceWith (content) } else { const content = j (`${i18nName} .t('${key} ')` ).find (j.ExpressionStatement ).__paths [0 ].value ; j (path).replaceWith (content) } } } actions[value] = actions[value] || [] actions[value].push (action (path)) })
获取中文的 key,完成替换 1 2 3 4 5 6 7 8 9 if (Object .keys (actions)?.length ) { const res = await this .#getKeysByValue (Object .keys (actions), {project : this .config .name }); Object .entries (res).forEach (([key,value] ) => { actions[value].forEach (cb =>cb (key)) }) }
在文件内导入 i18n 上面完成了查找替换,但还有一步漏掉了,文件可能没有导入 i18n 我们需要完成导入i18n,或者文件导入了,但是导入的名字叫 **i18N**``**I18n**``**I18N**,或者导入的是 **import {options} from '@utils/i18n'**
所以我们还需要再进行一次I8n的导入处理,但是执行处理却是要在 **确认文件内有未翻译的中文的时候,**所以I18n的处理也需要延迟执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #handleImportAst (ast ) { const imports = ast.find (j.ImportDeclaration ) const i18nAst = imports?.filter (path => if (path.value .source ?.value ?.includes ('/i18n' )) { return true } return false }) const i18nDefaultAst = i18nAst.filter (path => return path.value .specifiers ?.some (item =>type === 'ImportDefaultSpecifier' ) }) let importIi8n = false ,importDefaultI18n = false , i18nName = 'I18n' , createImportFn; if (!imports.__paths .length ) { importIi8n = false ,importDefaultI18n = false , i18nName = 'I18n' createImportFn = () => { const body = ast.find (j.Program ).__paths [0 ]?.value ?.body ; if (body) { const i18nDefaultImport = j (`import I18n from '@utils/i18n';\n` ).find (j.ImportDeclaration ).__paths [0 ].value body.unshift (i18nDefaultImport) } } } else if (!i18nAst.__paths .length ) { importIi8n = false ,importDefaultI18n = false , i18nName = 'I18n' createImportFn = () => { const firstImport = imports.__paths [0 ]; const i18nDefaultImport = j (`import I18n from '@utils/i18n';` ).find (j.ImportDeclaration ).__paths [0 ].value firstImport.insertAfter (i18nDefaultImport) } } else if (!i18nDefaultAst.__paths .length ) { importIi8n = false ,importDefaultI18n = true , i18nName = 'I18n' createImportFn = () => { const specifiers = i18nAst.__paths [0 ].value .specifiers specifiers.unshift (j.importDefaultSpecifier({ type : 'Identifier' , name : 'I18n' , })) } } else { const defaultName = i18nDefaultAst.find (j.ImportDefaultSpecifier ).__paths [0 ].value .local .name ; importIi8n = true , importDefaultI18n = true , i18nName = defaultName } return {importIi8n, importDefaultI18n, i18nName, createImportFn} }
其中 **createImportFn**就是对导入 i18n的处理动作;如果没有导入会在文件顶部 import I18n from '@utils/i18n',如果是import {options} from '@utils/i18n'会处理成 import I18n,{options} from '@utils/i18n'
之后如果文件内存在未翻译的中文,并且还没有导入 i18n就执行 createImportFn动作,最后将 ast 还原,进行文件替换
1 2 3 4 5 6 7 8 if (Object .keys (actions)?.length && !(importDefaultI18n && importIi8n)) { res.createImportFn ?.() } const target = ast.toSource ()fs.writeFileSync (filePath, target, {encoding : 'utf-8' });
提供配置文件
我们需要调用将中文进行上报的接口
我们可能有一些文件一些目录并不需要被扫描检测
我们最后的中英繁需要输出到一个文件
…..
有很多的内容并不适合写死在工具里,所以还需要对外提供一个允许配置的的能力
设计思路
将配置项以 JSON 文件形式输出
命令行工具读取 JSON 文件内容
使用 JSON.parse进行解析
定义配置文件名字为 translate.json,定义文件所在位置为项目根目录
允许配置项有
字段
类型
说明
entry
string
扫描的入口,默认为 src
ignoreDir
string[]
需要忽略的目录,即在src内有哪些目录不需要被扫描,示例: "ignoreDir": ["src/utils/language", "src/utils/offlineData", "src/pages/demo", "src/pages/test"]
ignoreFile
string[]
需要忽略的文件,即在 src 内,有哪些文件不需要被扫描,示例: "ignoreFile": ["src/utils/i18n.js"]
outputPkg
Object
将中英繁输出到那个文件,示例:"outputPkg": {"zh": "src/utils/language/zh.json", "hk": "src/utils/language/hk.json", "en": "src/utils/language/en.json"}
name
string
项目名字,即文案要归属的项目
down
string
下载项目翻译的接口
report
string
上报未翻译文案的接口
将中英繁输出到 en.json zh.json hk.json 扫描项目内的未翻译文案并对文案进行翻译之后,就需要将翻译下载到本地
确定中英繁翻译输出路径
1 2 3 const zhOutputPath = `${pangfs.getCurrPath()} /${config.outputPkg.zh} ` ;const hkOutputPath = `${pangfs.getCurrPath()} /${config.outputPkg.hk} ` ;const enOutputPath = `${pangfs.getCurrPath()} /${config.outputPkg.en} ` ;
调用接口获取到当前项目的所有翻译
1 2 3 4 5 6 7 const fetch = require ('node-fetch' );const res = await fetch (down, { method : 'POST' , headers : {'Content-Type' : 'application/json' }, body : JSON .stringify ({project}) }) let langPkg = await res.json ();
对数据进行处理,然后输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 const {zh, hk, en} = langPkg.reduce ((prev, curr ) => { prev.zh [curr.key ] = curr.zhCN ; prev.hk [curr.key ] = curr.zhTC ?? curr.zhCN ; prev.en [curr.key ] = curr.en ?? curr.zhCN ; return prev }, {zh :{}, hk : {}, en : {}}) fs.writeFileSync (zhOutputPath, JSON .stringify (zh, null , 2 )) fs.writeFileSync (hkOutputPath, JSON .stringify (hk, null , 2 )) fs.writeFileSync (enOutputPath, JSON .stringify (en, null , 2 ))
数据库结构设计
字段
类型
必须
唯一
说明
key
string
是
否
文案对应的key
project
string
否
否
文案所属项目
tags
string[]
否
否
文案的标签
zhCN
string
否
否
文案的简体中文
zhTC
string
否
否
文案的繁体中文
en
string
否
否
文案的英文
Translate-Server 后端服务 如何用 koa 写一个后端服务 1 2 3 4 5 6 7 8 9 10 11 12 13 npm init # 初始化项目 npm install koa # 安装 koa touch app.mjs # 创建入口文件 import Koa from "koa"; // 对koa实例化 const app = new Koa(); // 设置返回 hello world app.use(async (ctx, next) => { ctx.body = 'hello world'; }) // 监听10086端口 app.listen(10086, () => {console.log('启动完成, http://127.0.0.1:10086')});
执行 node app.mjs启动服务
访问:http://127.0.0.1:10086可以看到输出 hello world
如何写接口 ctx 获取请求路径 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import Koa from "koa" ;const app = new Koa ();app.use (async (ctx, next) => { if (ctx.request .path === '/' ) { ctx.body = '访问路径 /' ; } else { ctx.body = 'hello world' ; } }) app.listen (10086 , () => {console .log ('启动完成, http://127.0.0.1:10086' )});
koa-router 上面的方案很明显过于麻烦,所以社区有提供现成的解决方案 koa-router
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import Koa from "koa" ;import KoaRoute from "koa-router" ;const app = new Koa ();const router = new KoaRoute ();router.get ("/api/findWord" , async (ctx,next) => { ctx.body = { code : 0 , message : 'success' , data : '/api/findWord' } }); router.post ("/api/updateWords" , async (ctx,next) => { ctx.body = { code : 0 , message : 'success' , data : '/api/updateWords' } }); app.listen (10086 , () => {console .log ('启动完成, http://127.0.0.1:10086' )});
如何获取客户端传参 接口完成了,但正常情况我们还需要给客户端提供入参的功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 get` `ctx.request.query post` `ctx.request.body import Koa from "koa"; import KoaRoute from "koa-router"; const app = new Koa(); const router = new KoaRoute(); // get 请求 router.get("/api/findWord", async (ctx,next) => { // 获取入参 const params = ctx.request.query ctx.body = { code: 0, message: 'success', data: '/api/findWord' } }); // post 请求 // 如果路径相同 请求方式不同 不会走到这里来 这就是 .get 和 .post 的意义 router.post("/api/updateWords", async (ctx,next) => { // 获取入参 const params = ctx.request.body ctx.body = { code: 0, message: 'success', data: '/api/updateWords' } }); // 监听10086端口 app.listen(10086, () => {console.log('启动完成, http://127.0.0.1:10086')});
如何链接 Mongodb 数据库 1. 安装 mongoose 2. 定义数据模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import mongoose from 'mongoose' ;const Word = new mongoose.Schema ({ key : { type : mongoose.Schema .Types .String , require : true }, project : mongoose.Schema .Types .String , tags : [mongoose.Schema .Types .String ], zhCN : mongoose.Schema .Types .String , en : mongoose.Schema .Types .String , zhTC : mongoose.Schema .Types .String , }, {timestamps : true }) export const WORD = mongoose.model ('Word' , Word );
3. 连接数据库
mongodb://数据库连接协议i18n数据库名字admin拥有对 i18n 这个数据库进行增删改查权限的账号Aaaaaaaa1!账号密码
1 2 3 4 5 6 7 mongoose.connect ('mongodb://admin:Aaaaaaaa1!@127.0.0.1:27017/i18n' , { useNewUrlParser : true }, err => if (err) { console .log ('出错---------->' , err) } else { console .log ('链接成功' ); } })
mongodb 如何进行增删改查、批量操作 对于 mongodb 的操作将会使用 mongoose,mongoose 是 nodejs 用来操作 mongodb 的库,增删改查需要详细阅读此章节 https://mongoosejs.com/docs/api/model.html
基于上面的代码,当请求到 updateWords接口时,执行 updateWords方法
1 router.post ("/api/updateWords" , updateWords);
增加单个数据 create 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import {WORD } from '../db/index.mjs' ;const updateWords = async (ctx,next ) => { try { await WORD .create ({ key : 'SieIn6ar' , project : 'kiki-web' , zhCN : '交易记录' }) ctx.body = { code : 0 , message : '添加成功' } } catch (error) { ctx.body = { code : 1 , message : error.message } } }
批量增加数据 insertMany insertMany与 create的区别就是 insertMany的参数是一个数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import {WORD } from '../db/index.mjs' ;const updateWords = async (ctx,next ) => { try { await WORD .insertMany ([ { key : 'SieIn6ar' , project : 'kiki-web' , zhCN : '交易记录' }, { key : 'pMmnAhpS' , project : 'kiki-web' , zhCN : '还款记录' }, ]) ctx.body = { code : 0 , message : '添加成功' } } catch (error) { ctx.body = { code : 1 , message : error.message } } }
简单修改
根据id查找并修改 Model.findByIdAndUpdate()
根据输入的条件查找第一个符合的并修改 Model.findOneAndUpdate()
根据输入的条件查找第一个符合的并修改与 findOneAndUpdate相同Model.updateOne()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import {WORD } from '../db/index.mjs' ;const updateWords = async (ctx,next ) => { try { await WORD .updateOne ({_id : '62d28503f598d775cee26a9c' }, {zhCN : '修改这条数据的中文' }) ctx.body = { code : 0 , message : '添加成功' } } catch (error) { ctx.body = { code : 1 , message : error.message } } }
批量修改
Model.update()Model.updateMany()
1 await WORD .update ({key : 'SieIn6ar' }, {zhCN : '修改所有 key 为 SieIn6ar 数据的中文' })
查找
Model.find()Model.findById()Model.findOne()
查找数据是非常常用的操作,想要熟练的应用,建议详细阅读 mongodb 操作符 https://www.mongodb.com/docs/manual/reference/operator/query/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 await WORD .find ({ tags : { $all : ['msg-key' ] }, $or : [ {zhCN : {$exists : false }}, {zhCN : '' }, {en : {$exists : false }}, {en : '' }, {zhTC : {$exists : false }}, {zhTC : '' }, {en : {$regex : '[\u4e00-\u9fa5]' }} ] }, {'__v' : 0 }, {sort : {updatedAt : -1 }})
第2个参数:不需要返回那些字段,0 不反回 1 返回
第3个参数 sort 排序,根据 updatedAt 倒叙排列
删除【物理删除】
Model.deleteOne()Model.deleteMany() 批量删除Model.findByIdAndDelete()Model.findByIdAndRemove()Model.findOneAndDelete()Model.findOneAndRemove()
1 await WORD .findOneAndDelete ({_id : '62d28503f598d775cee26a9c' })
批量操作【增删改】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 await WORD .bulkWrite ([ { insertOne : { document : { key : 'community_select' , zhCN : '选择' , project : 'kiki-web' } } }, { deleteOne : { filter : { _id : '62d28503f598d775cee26a9c' } } }, { updateMany : { filter : { zhCN : '登陆' }, update : { zhCN : '登录' } } } ])
导入已有翻译接口设计 背景: 由于项目先进行的开发,之前的国际化翻译都是存在于项目内的,所以首先就需要先将已有的翻译导入数据库;同时在日常开发或修bug或其他场景下,我们的项目是已经在编辑器中打开的情况下,这个时候添加个新的文案,让开发再打开浏览器,输入地址添加文案,很明显不如直接在项目内添加;基于以上两种考虑,故设计此接口
入参设计
字段
类型
必须
说明
lang
zhCN``zhTC``en是
因项目内 中英繁 语言文件是分开存放的,所以上传需要告知所传内容是 简体 繁体 英文
pkgData
`{type: ‘add’
‘update’, next: string, key: string}[]`
是
project
string
是
上传的文案归属于哪个项目
出参设计 正常告知操作状态即可,成功 or 失败
完整接口代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import { WORD } from '../db/index.mjs' export const uploadLangPkg = async (ctx, next ) => { const {lang, pkgData, project} = ctx.request .body ; try { const {addData, updateData} = pkgData.reduce ((prev, curr ) => { if (curr.type === 'add' ) { prev.addData .push ({key : curr.key , project, [lang]: curr.next }) return prev; } prev.updateData .push ({updateOne : { filter : {key : curr.key , project}, update : {[lang]: curr.next } }}) return prev }, {addData : [], updateData : []}) ctx.body = { message : 'success' } if (addData.length ) { WORD .insertMany (addData) } if (updateData.length ) { WORD .bulkWrite (updateData) } } catch (error) { console .log ("更改失败" , error) ctx.body = { error } } }
命令行工具进行文案上报的接口设计 背景: 命令行工具扫描出项目内未翻译的中文文案之后,需要将文案上报至服务端,由服务端生成文案的key,以保证同样的文案 key 值一致;故设计此接口
入参设计
字段
类型
必须
说明
values
string[]
是
允许工具将扫描出来的中文一次性上报上来,以提高效率,故设计为 string[]
project
string
是
文案所归属的项目
出参设计
key是中文对应的 keyvalue是上报的中文
完整接口代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import {WORD } from '../db/index.mjs' ;import goodid from 'goodid.js' ;export const getKeysByValue = async (ctx, next ) => { try { const {values,project} = ctx.request .body ; const $or = values.map (value =>zhCN : value})); const words = await WORD .find ({$or}); const body = {}; const update = [] values.forEach (value => const valueWords = words.filter (word =>zhCN === value); if (!valueWords?.length ) { const key = goodid (8 ); body[key] = value; const action = {insertOne : {document : { key, zhCN : value, project }}} update.push (action) return } let valueWord = valueWords.find (word =>project ?.includes (project)) if (valueWord) { body[valueWord.key ] = value; return } valueWord = valueWords[0 ]; const key = goodid (8 ); body[key] = value; const action = {insertOne : {document : { key, zhCN : valueWord.zhCN , zhTC : valueWord.zhTC , en : valueWord.en , project }}} update.push (action) }) ctx.body = body if (update.length ) { await WORD .bulkWrite (update) return } } catch (error) { console .log ("获取 key 出错" , error) } }
如何把客户端程序打包进后端服务,并给浏览器返回 如果将 客户端程序 单独部署的话,需要一个 web 容器 nginx或者 Apache,还需要安装,太麻烦了,而我们本身已经有 node 写的后端服务了,那就直接用 后端服务作为容器;
客户端请求来了,如果是请求的静态资源,我们直接将资源返回就好了,可以省去 nginx的安装配置过程,同时还不需要解决跨域问题,所以需要用 后端服务 实现一个 web 容器功能
怎么写 Koa 中间件 用 koa 来进行静态资源的分发,社区有提供 koa-static中间件,但它主要是针对传统的多页面应用,而我们现在的客户端程序基本都是单页面应用。
单页面应用的特点就是只有一个 html 文件,使用的是客户端路由,路径切换是客户端根据不同路径渲染不同组件实现的。
所以使用 koa-static就会造成一个问题,当客户端请求 http://127.0.0.1:10086/translate时,koa-static找不到 translate.html文件,就会 404 报错。
所以我们需要自己写一个 koa-static中间件来实现静态资源分发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import path from 'path' ;import assert from 'assert' ;import send from 'koa-send' ;export const serve = (root, opts = {} ) => { assert (root, 'root directory is required to serve files' ) opts.root = path.resolve (root) opts.index = opts.index ?? 'index.html' return async (ctx, next) => { const url = ctx.request .url ; await next () if (url.startsWith ('/api' )) return if (ctx.method !== 'HEAD' && ctx.method !== 'GET' ) return if (ctx.body != null || ctx.status !== 404 ) return try { const path = opts.filePath ?.(url) await send (ctx, path || ctx.path , opts) } catch (err) { if (err.status !== 404 ) { throw err } } } } export default serve
Koa中间件的本质就是一个接受 ctx, next的函数,所以我们 serve方法就返回了一个这样的函数,因为我们还需要提供给用户一些配置,例如静态资源存在哪个目录下,所以这里采用的是闭包形式,这样可以保存用户的配置,然后在应用这个中间件
1 2 3 4 5 6 7 8 9 10 11 12 import KoaStatic from './middleware/static.mjs' ;app.use (KoaStatic ('static' , { filePath : (path ) => { const reg = /\.+/ if (!reg.test (path)) { return '/' } return path } })) filePath`如果请求的资源路径包含 ` .`说明请求的是 ` .css `` .js ` 等静态资源,直接返回即可,如果不是,说明请求的是页面,那就返回跟路径,即会返回 ` index.html
Translate-Client 客户端程序 设想:
客户端需要可以可视化的查看到项目的所有翻译,同时提供一些基本的搜索过滤能力,例如搜索key,搜索中英繁文案
项目内原先已有国际化的文案,需要进行上传到数据库
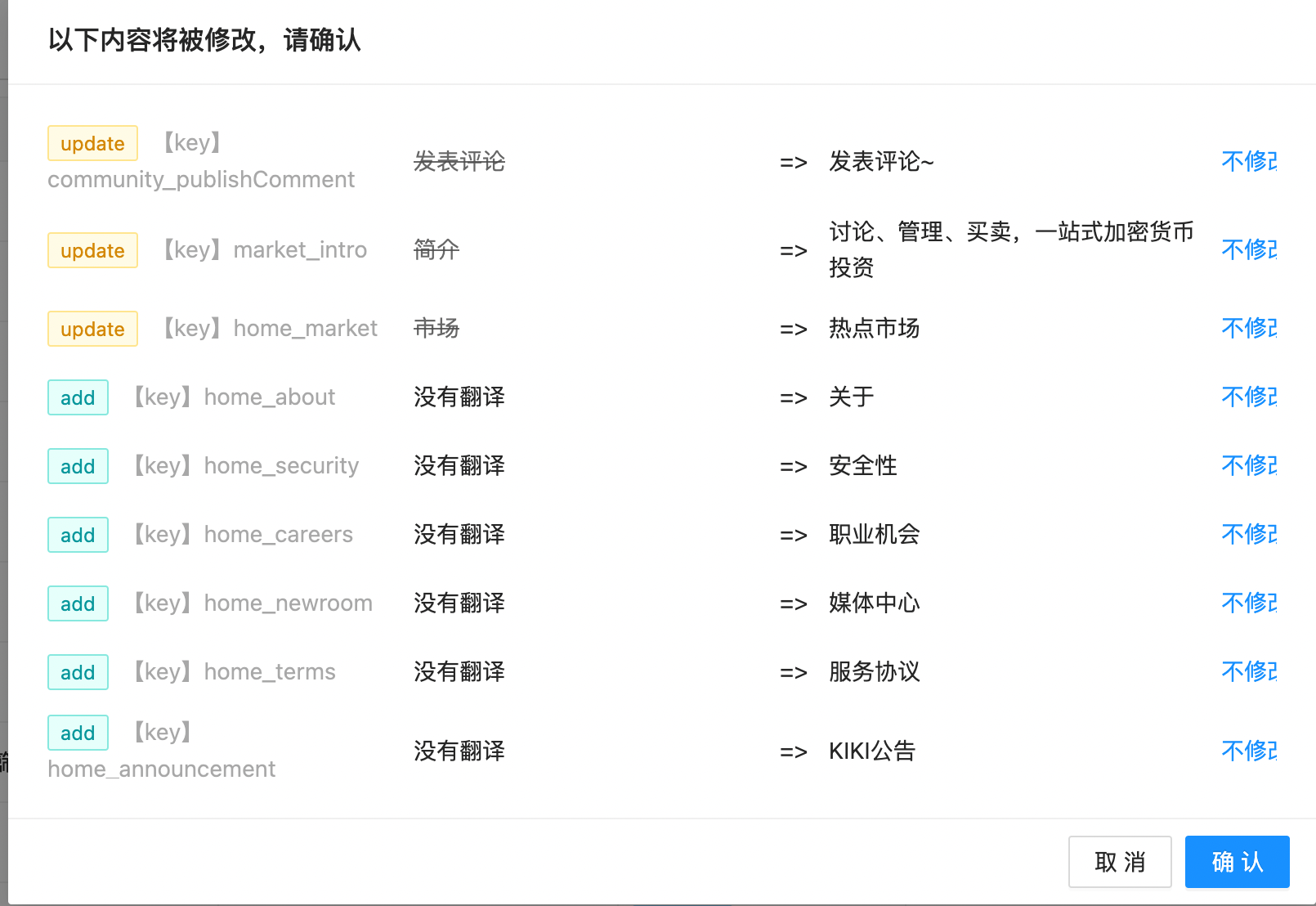
2.1. 后期在开发过程中,肯定也会存在直接在项目内修改翻译的操作,所以将翻译文件上传到数据库并不是一次性的操作,所以再上传的时候,要进行检测,那些是数据库中已经存在的,存在的不需要上传;那些是对文案进行了修改,修改的显示出修改的内容
需要允许翻译团队在平台上进行添加翻译,并且是批量添加,翻译团队添加的时候,只需要输入中英繁文案即可,不需要考虑 key;当新需求开发的时候,会批量新增一些文案,如果一个一个的去添加,效率太低,体验也差
3.1. 添加的时候,同样需要检测那些数据库已有
3.2. 如果是接口报错的,翻译需要由开发去添加,这个时候需要由开发指定key
项目中可能有一些翻译是重复的,需要可以被检测出来,然后手动处理
数据库管理的翻译内容并不止一个项目,有些翻译可能在其他项目已经存在了,所以添加翻译的时候,需要跨项目检测,进行提示,纠正翻译,尽量使翻译内容统一
在顶层获取到 translate-server 的数据 基于以上的设想,所以设计,查看项目翻译的列表与添加翻译的页面均为子路由,在他俩的父路由将数据库的所有翻译数据全部请求回来
父子路由
list为列表页面add为添加页面:project为项目,查看某个项目内的翻译:role为角色,不存在的话,添加翻译只需要输入中英繁,存在的话,添加翻译还需要设置 key
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import { BrowserRouter , Route , Routes } from 'react-router-dom' import { Translate } from '@pages/list' ;import { AddTranslate } from '@pages/add' ;import {Main } from '@pages/Main' ;const translateList = [ { path : ':project/list' , component : Translate }, { path : ':project/add/:role' , component : AddTranslate }, { path : ':project/add/*' , component : AddTranslate }, ] export const MainRoute = ( return ( <BrowserRouter > <Routes > <Route path ="/translate" element ={ <Main /> }> {translateList.map(item => (<Route key ={item.path} path ={item.path} element ={ <item.component /> } />))} </Route > </Routes > </BrowserRouter > ) }
在父路由内请求到所有数据,然后通过 context 传到子路由 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import { ConfigProvider , Form } from 'antd' import React , { useEffect, useState, createContext } from 'react' ;import { Link , Navigate , Outlet , useLocation } from 'react-router-dom' import { fetchWords } from '@src/api' ;import { TContext } from '@src/context' ;export const Main : React .FC = () => { const [dataSource, setDataSource] = useState ([]) const [form] = Form .useForm (); const getData = async ( const res = await fetchWords (); setDataSource (res); } useEffect (() => { getData () }, []) return ( <TContext.Provider value ={{dataSource, getData , form }}> <ConfigProvider autoInsertSpaceInButton ={false} > <Outlet /> </ConfigProvider > </TContext.Provider > ) }
列表内取context传下来的内容,然后根据项目筛选出仅归属于当前项目的文案 1 2 3 4 5 6 7 import React , {useContext} from 'react' ;import { TContext } from '@src/context' ;import { useParams } from 'react-router-dom' ;const {dataSource, getData} = useContext (TContext )const {project} = useParams ()dataSource?.filter (item =>project === project)
导入已有翻译 设计思路
由前端读取上传文件的内容,然后进行 JSON 解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 const renderJson = (file: File ) => { const fileRender = new FileReader (); return new Promise ((resolve, reject ) => { fileRender.onload = (evt ) => { resolve (evt?.target ?.result ) } fileRender.onerror = (ev ) => { reject (ev); } fileRender.readAsText (file); }) } const renderLang = async (content?: string ) => { if (!content) { return Promise .reject (new Error ('语言包格式错误' )) } try { const lang = JSON .parse (content); return Promise .resolve (lang); } catch (error) { return Promise .reject (new Error ('语言包格式错误' )) } }
将解析后死亡 JSON 进行处理,过滤出那些是添加,那些是修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 const handleUploadData = ({langData, lang}: FormValue ) => { const keys = Object .keys (langData); const dataSourceMap = dataSource.filter (item =>project === PROJECT ).reduce <{[k : string ]: TRecord []}>((prev,curr ) => { if (prev[curr.key ]) { prev[curr.key ].push (curr) return prev; } prev[curr.key ] = [curr]; return prev; }, {}) const list = keys.reduce <UploadConfirmReq ['list' ]>((prev, k ) => { const v = langData[k] const kList = dataSourceMap[k] if (!kList?.length ) { const data :UploadConfirmReq ['list' ][number ] = {key : k, curr : '' , next : v, type : 'add' } prev.push (data); return prev; } kList.forEach ((item ) => { const curr = item[lang as keyof TRecord ] as string ; if (curr !== v) { const data :UploadConfirmReq ['list' ][number ] = {key : item.key , curr, next : v, type : 'update' } prev.push (data); } }) return prev; }, []) return list }
将修改或添加的文案呈现给用户,让用户进行二次确认,确认之后调用后端上传接口
1 2 3 4 5 6 const req = await openUploadConfirm (data)const res = await fetchUploadLangPkg ({ project : PROJECT as string , pkgData : req, lang : lang.lang })
检测重复项:空间换时间 项目内可能会存在一些重复的 zhCN``zhTC``en``key,我们需要将其检测出来,然后进行处理
在一维数组内,如果我们要检测重复项,常规方法可以循环套循环,即
1 2 3 4 5 6 7 8 9 10 11 const tableData = dataSource;const repeatData = [];for (let i = 0 , i <= tableData.length , i ++) { let key1 = tableData[i].key for (let j = 0 , j <= tableData.length , j ++) { let key2 = tableData[j].key if (key1 === key2) { repeatData.push (tableData[j]) } } }
但是这样二层循环非常耗费时间,时间复杂度为 O(n2),效率太低,肯定是不可取的,所以可以采用算法的常用思想:用空间换时间
将数组转为对象,key 为 zhCN,value 为 zhCN 相同的 item 数组,只要 value 长度大于 1,就说明存在重复的内容
1 2 3 4 5 6 7 let tableData = dataSource;let repeatData : any = {};tableData.forEach (item => repeatData[item.zhCN ] = repeatData[item.zhCN ] || []; repeatData[item.zhCN ].push (item) }) tableData = Object .values (repeatData).filter ((value ) => (value as TRecord [])?.length > 1 )?.flat () as TRecord []
保存草稿 在 mac chrome 浏览器中,在触摸板上进行左滑右滑浏览器会前进后退,很容易造成添加翻译的时候,写了一大堆,结果一下子全都没有了,所以需要一个可以保存草稿的能力
保存草稿利用 indexDB 进行存储,可存储空间更大
设计思路
在用户进入添加页面时,获取草稿内容,获取显示在页面之后,删除草稿
在用户没有点击保存按钮而页面销毁时进行保存草稿
在用户点了保存按钮,保存成功之后删除草稿
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 import PouchDB from 'pouchdb-browser' ;import { IFormWord } from '@src/types' ;import pick from 'lodash/pick' type IWords = (IFormWord & {_rev?: string ;index?: number })const createDB = ( let db : PouchDB .Database ; return () => { if (db) { return db } db = new PouchDB ('draft' ); return db } } const getDB = createDB ();export const getDraft = async (): Promise <IWords []> => { try { const res = await getDB ().allDocs ({include_docs : true }) const words : IWords [] = res.rows ?.map ((item ) => pick (item.doc , ['_id' , 'en' , 'zhTC' , 'zhCN' , 'key' , '_rev' , 'index' ])) return words.sort (({index: aIndex = 0 },{index: bIndex = 1 } ) => aIndex - bIndex) } catch (error) { return [] } } export const saveDraft = async (words: IFormWord[] ) => { const data = words?.map (({en = '' , zhCN = '' , zhTC = '' , key = '' }, index ) => ({en, zhCN, zhTC, key, index})) console .log ('存储草稿' , data) try { await getDB ().bulkDocs (data) } catch (error) { console .log ('保存失败' , error) } } export const deleDraft = async (words: IWords[] ) => { const data = words?.map ((item ) => ({...pick (item, ['_id' , '_rev' ]), _deleted : true })) try { await getDB ().bulkDocs (data) } catch (error) { console .log ('删除失败' , error) } } useLayoutEffect (() => { initForm () window .addEventListener ('beforeunload' , handlePageDestroy); return () => { handlePageDestroy () clearInterval (timer.current ) window .removeEventListener ('beforeunload' , handlePageDestroy); } }, []) const initForm = async ( let tableData = await getDraft () if (!tableData?.length ) { tableData = Array (10 ).fill (1 ).map (() => ({_id : goodid (8 ), key : '' , zhCN : '' , zhTC : '' , en : '' })); } setTableData (tableData); const formValue = tableData.reduce <{[key : string ]: IFormWord }>((prev, curr, index ) => { prev[index.toString ()] = curr; return prev; }, {}) form.setFieldsValue (formValue) deleDraft (tableData); } const handlePageDestroy = ( if (stateRef.current .isSaved ) { return } const formValue = form.getFieldsValue () saveDraft (Object .values (formValue)); } const onSave = async ( try { stateRef.current .isSaved = true ; navigate (-1 ) } catch (error) { console .log ('添加失败' , error) message.error ('添加失败' ) } }
后续规划 在 translate-cli 中,添加检测还在使用的 key 的命令 在实际使用的过程中,我们发现翻译文件内存在非常多并没有使用的文案,所以需要添加一个检测那些 key 在使用,那些 key 没有再使用,再在获取翻译输出到 zh.json``hk.json``en.json时,只获取还在使用的文案
设计思路
遍历项目内所有的 js``jsx文件
查找文件内导入 i18n的默认导入名
查找 i18n.t节点,记录被包裹的字符串
将所有的字符串上报
后端将上报的字符串添加一个在使用的标识,没有再使用的添加一个未使用的标识
VS code 插件,持续提升开发体验 运行命令行检测还是略麻烦,更好的体验是在开发过程中,在文件保存时进行检测,研发完全无感
提供 js 的 translate-cli 配置 如果工具要提供给其他团队使用,他们使用的国际化工具并不一定就是 import I18n from '@utils/i18n'``I18n.t,所以更好的是导入的方法,由使用方自己提供,这种场景下 JSON 配置就不适用了,最好的是 js 文件配置,工具内调用使用方提供的 js 配置文件
方向一: 使用 require 加载指定路径的 js 文件,似乎并不行
方向二: 使用 VM模块,执行 js,未测试
方向三: …
附件 https://space.dingtalk.com/s/gwHOA_c7pALOEWYPSgPaACBkMzM0ZmM2ODQxN2Q0YWUzOGUwNjBhNmZjMzgzNjZmMQ
密码: FuPW