你有没有见过这种文件内容,狗屁不同,让人梦回火星文年代。一个人很难这辈子都没碰见过乱码,没在深夜见过锟斤铐的人,不足以语人生。但乱码到底是怎么来的?知名乱码锟斤铐又为何如此常见?
乱码是如何产生的
要理解乱码,首先需要知道计算机是如何储存文字的,计算机只能储存0和1这些二进制数字,无论是我们文本里的数字、字母、汉字、emoji、都需要用某种方式转换成二进制数字进行储存,需要的时候再读出来。1963年 ANSI(美国国家标准学会)推出了ASCII,全称为“美国信息交换标准代码”,作为计算机及其他设备的文本字符编码标准,ASCII支持的字符,包含0~9的阿拉伯数字,小写英文字母,大写英文字母,常用的英文符号以及控制字符负责对应换行回车等特殊的控制功能。
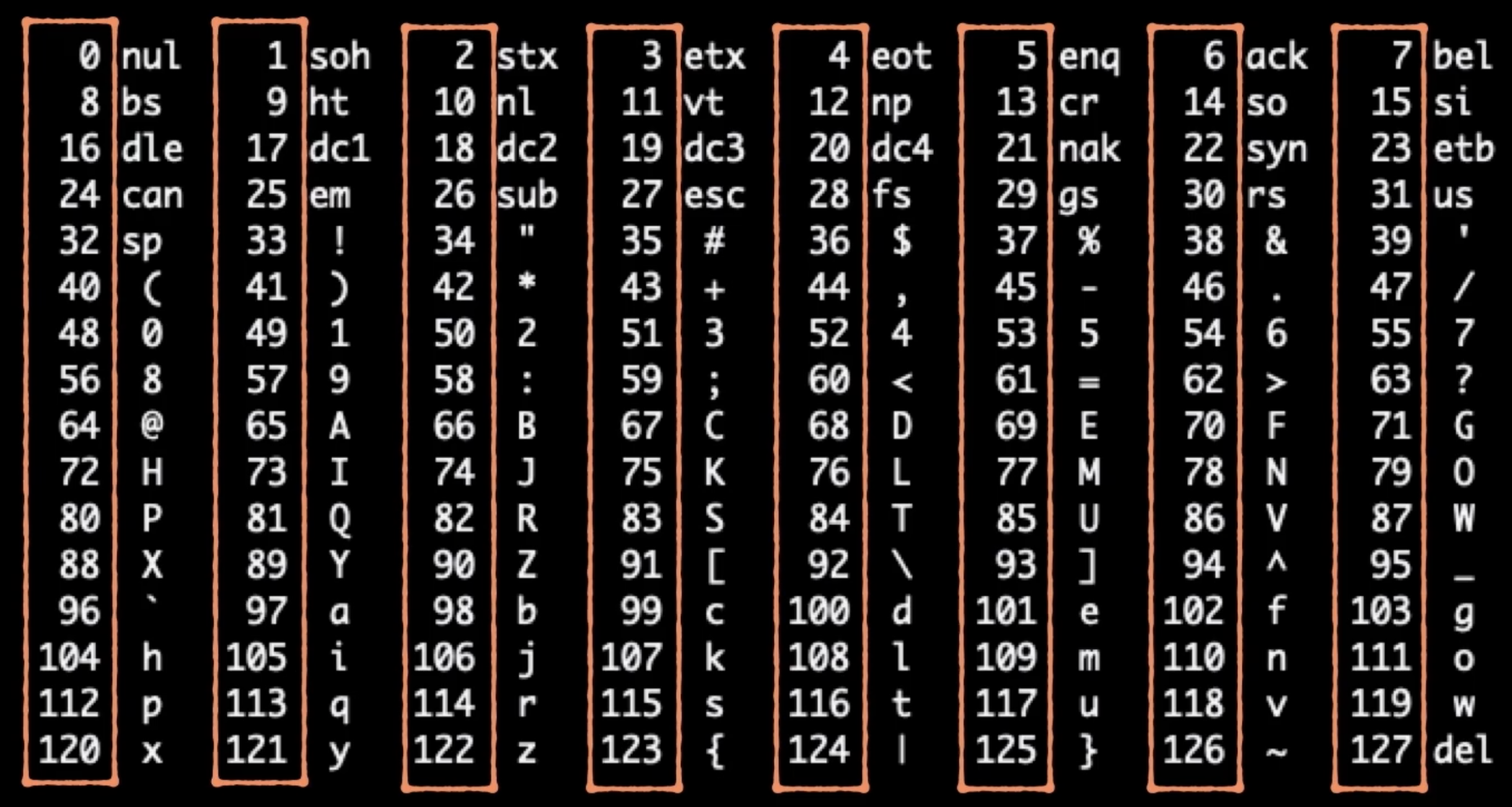
每个字符都有一个对应的数字,叫做码点,ASCII字符的码点为0~127之间的数字,比如大写字母A根据ASCII的标准,对应码点65。标准所支持的所有字符及其对应码点的集合叫做字符集,所以这个是ASCII字符集。
ASCII字符集一共包含128个字符,计算机可以储存码点的二进制,由于最大的码点是127,二进制的长度都会小于或等于7比特,也就是7个0或1,但由于计算机一般以8比特即一字节为基本单位进行读写,所以为了凑整这些二进制被储存时会在开头留0,用固定的8比特长度来储存每个字符,这种从字符到计算机能够储存的内容之间的映射叫做编码。
比特和字节的关系:
比特(bit): 电脑是以二进制存储以及发送接收数据的。二进制的一位,就叫做 1 bit。简写为小写字母 “b”
字节(Byte): 字节 Byte 和比特 bit 的换算关系是 1 Byte = 8 bit ,简写为大写字母 “B”
千字节(KB): 需要了解的是,1 KB 并不是一千字节,因为计算机只认识二进制,所以在这里的 KB,是 2 的 10 次方,也就是 1024 个字节
很多表示存储单位的地方都把 B 写成 b,造成了大家认知的混乱。其实在存储单位计量中出现 b 的地方,它的意思仍然是 B,不要因为 bit 的缩写是 b 就被误导了,在存储计量中是不会用 比特,千比特 这种单位的。
| 字符 | 码点 | 二进制码点 | 储存在计算机的内容 |
|---|---|---|---|
| NUL | 0 | 0 | 00000000 |
| SOH | 1 | 1 | 00000001 |
| … | … | … | … |
| 0 | 48 | 110000 | 00110000 |
| 1 | 49 | 110001 | 00110001 |
| … | … | … | … |
| A | 65 | 1000001 | 01000001 |
| B | 66 | 1000010 | 01000010 |
| … | … | … | … |
| ~ | 126 | 1111110 | 01111110 |
| DEL | 127 | 1111111 | 01111111 |
但美国佬制定的 ASCII 编码一共就适用于128个字符,虽然英文文本ok,但其他语言就不够用了,比如法语带音符的字母,中文、汉字、日文、片假名等都统统表示不了。于是不同国家和地区开始制定自己的编码标准,比如大陆有国家标准总局制定的于1981年开始实施的GB2312,港澳台有在1984年开始流行的Big5,后来还有对GB2312进行扩展的GBK,收录了简繁体汉字、日文、韩文等。
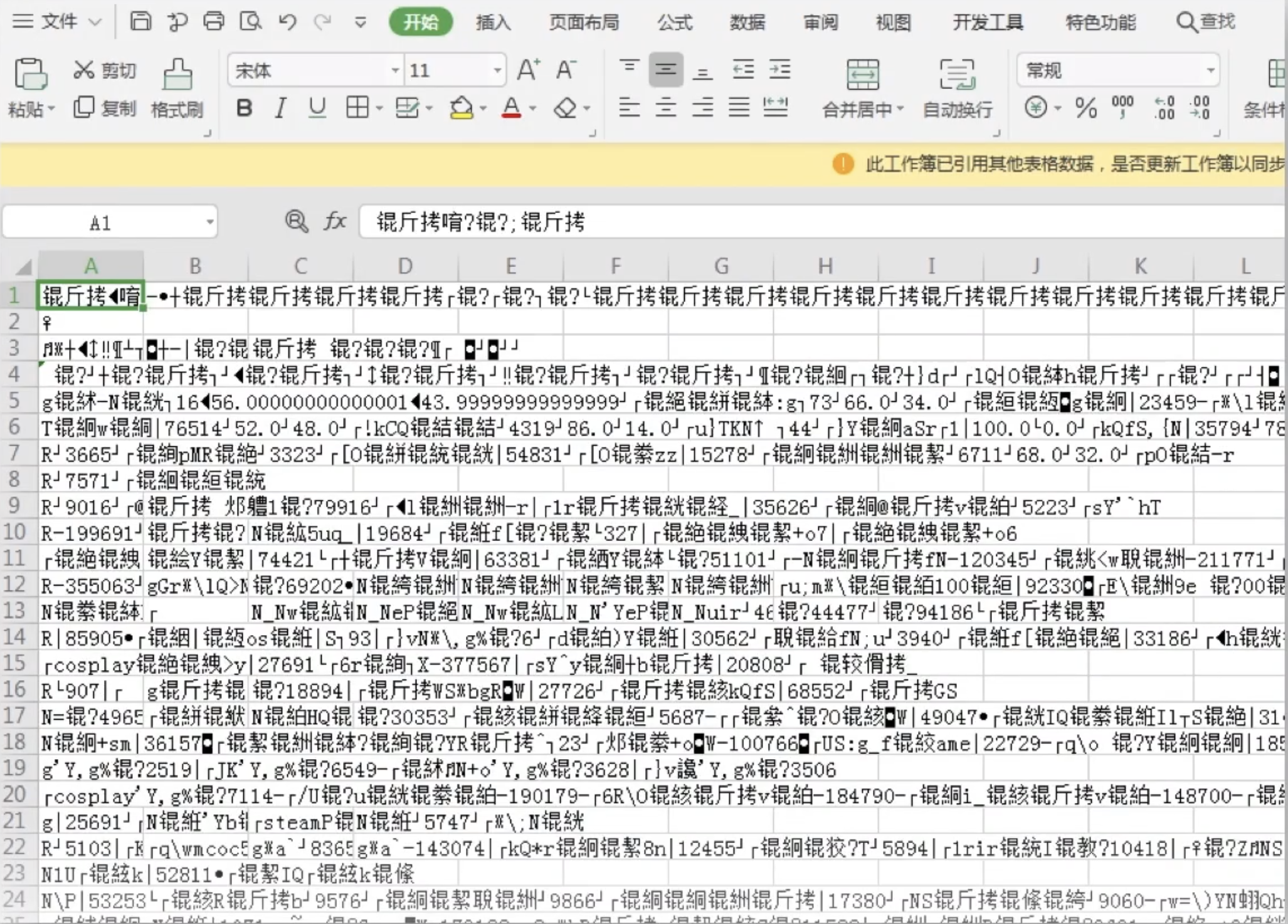
但标准不统一时,乱码问题也随之产生,因为计算机内存里的同一个数字在不同字符集里代表的可能是完全不同的字符。如果你用 GBK编码的文本编辑器给你香港的朋友写个文档发送过去,在用Big5的文本编辑器读取后就会变成这样,于是大家急需一种更通用的字符编码,支持不同语言的文字。
| 存在计算机里的内容 | 码点 | 字符 |
|---|---|---|
| 1011101011000011 | BAC3 | 好 |
| 1011101011000011 | BAC3 | 疑 |
1991年 unicod 字符集发布,目标在于让世界上每个人都能在电脑上阅读自己的文字。随着版本的迭代,Unicode 囊括的字符越来越多,包括汉字、平片假名、藏文、阿拉伯文甚至古象形文字。2010年 emoji 也被纳入Unicode,如今 Unicode 的已经包含了超过14万个字符,Unicode的每个字符也有对应码点,许多语言都有可以用于查询 Unicode 字符码点的内置函数,比如说Python的 ord 函数,JavaScript的codePointAt函数,但需要注意的是字符集只是字符及字符对应码点的集合,不代表字符一定会以对应码点被储存在计算机里,字符编码才是真正定义了从字符到计算机储存内容的映射。
那最简单的编码规则自然就是把字符对应的码点直接以二进制储存在计算机里。
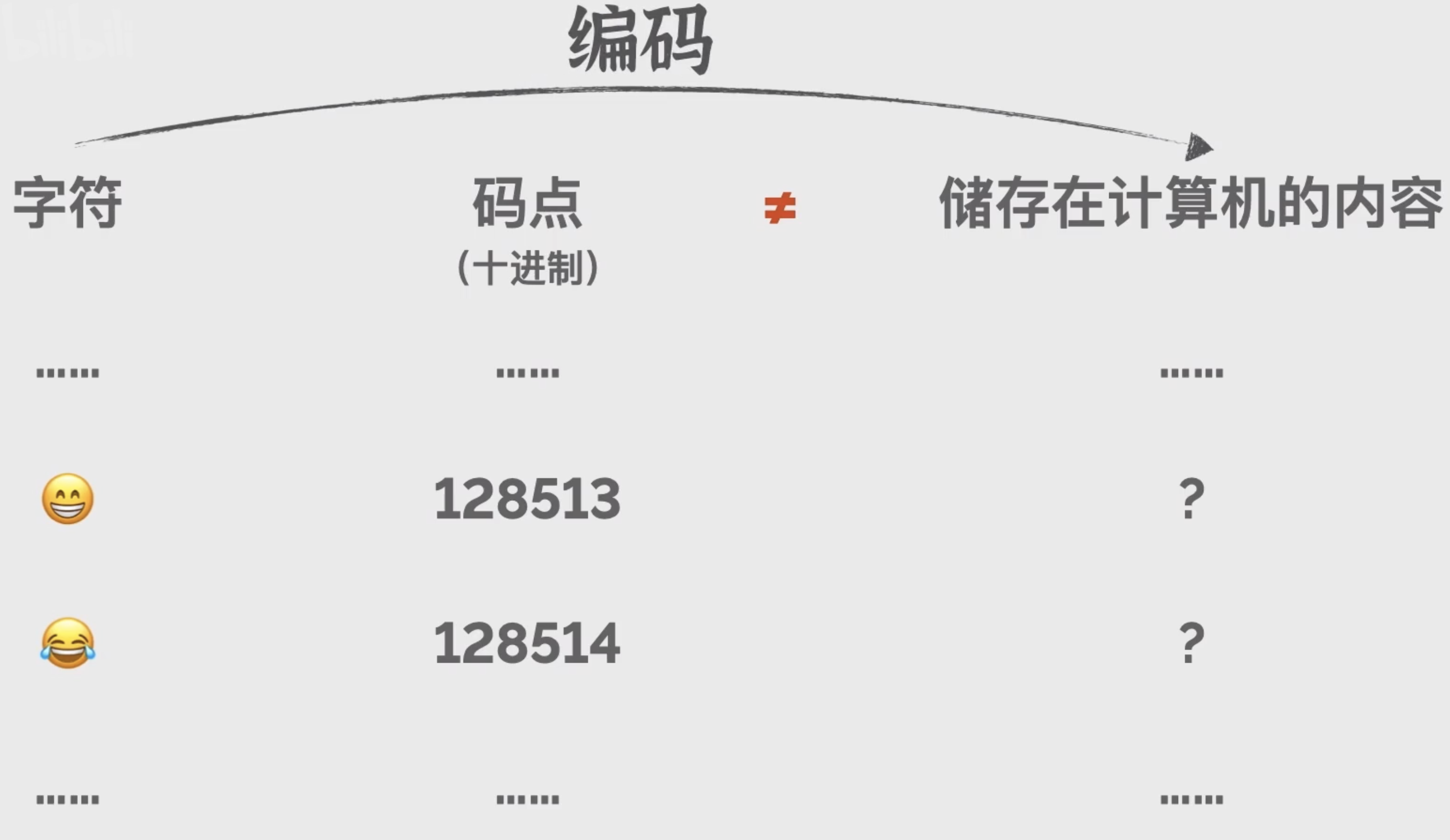
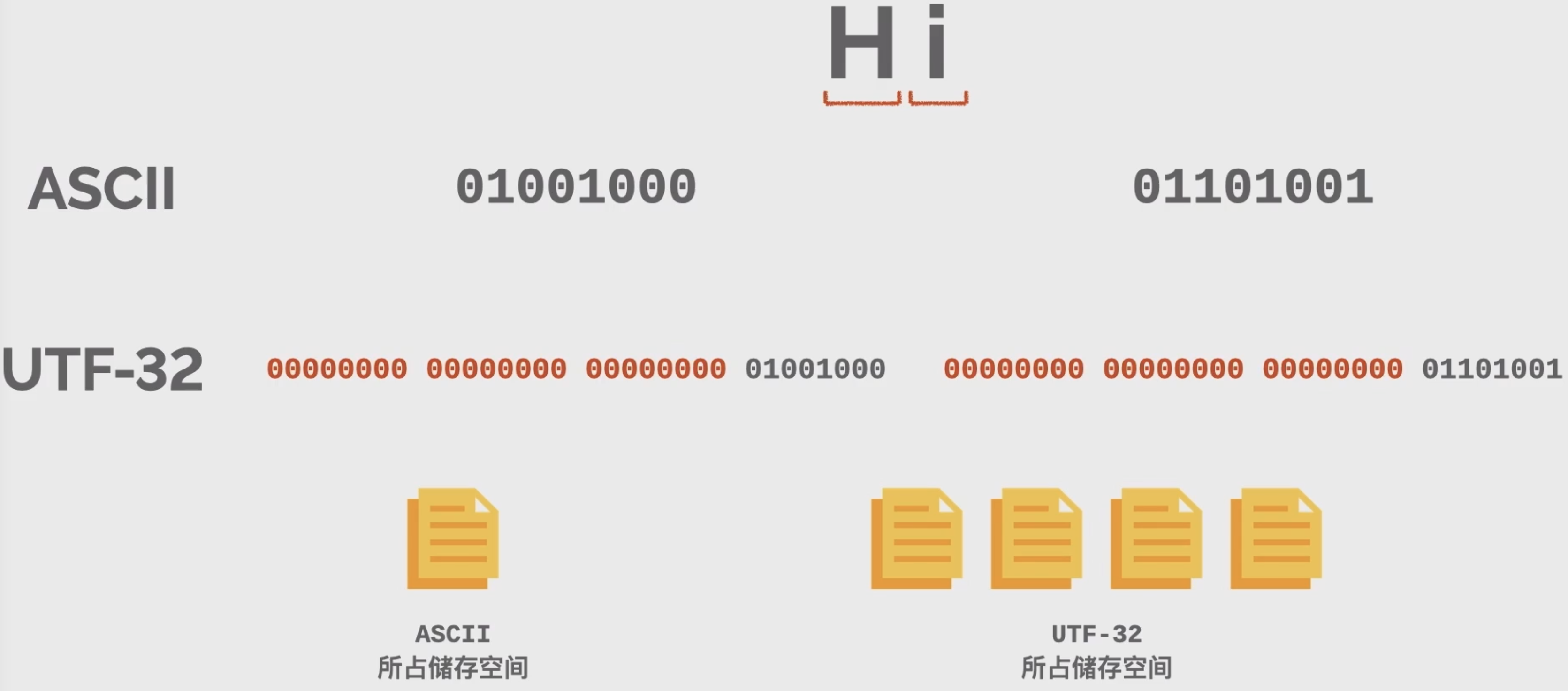
UTF-32这个编码就是针对Unicode这样做的,之前了解的 ASCII 编码也是针对 ASCII 字符集这样做的,但由于Unicode 字符集海纳百川有容乃大,这乃大了也随之带来一个问题,就是单个字符需要的储存空间更大,像 ASCII 只有128个字符,8比特以内的二进制数字就足以表示所有字符,但Unicode如今已经囊括了10万多个字符,比如这个 💩 emoji, Unicode 里面对应10进制码点 128169,二进制为 11111010010101001 整整有17比特,而且还不能让这个二进制数字直接跟在前面数字的屁股后面,因为会分不清每个字符是从哪里到哪里。因此UTF-32让每个字符都以32比特即4字节的长度来储存,位数不够就在前面补0。

32比特足够表示unico的里面所有字符,固定的长度也能够帮助计算机明确每个字符的截断范围,这看起来好像没什么问题,但让英文使用者有点不爽。 ASCII 编码的每个英文字符只要一字节,现在UTF-32要4字节,这相当于相同内容的英文文本。UTF-32所占空间会是ASCII的4倍,而且由于英文字符的码点在Unicode里数字较小实质上很多,空间都用来放0了。UTF-32也没让汉字使用者占便宜,GBK里一个汉字只占俩字节,相当于用UTF-32的话,空间会多占一倍。

为了改善空间效率拯救字符苍生的UTF-8在1992年诞生。Utf-8是针对Unicode的可变长度编码,不同于编码后,长度固定为32比特的utf-32。Utf8针对不同字符编码后的长度可以是32比特,24比特,16比特,8比特。
具体规则是码点在 0-127 范围的字符,直接映射为一字节长度的二进制数;码点在 128~2047 范围的字符映射为二字节的二进制数,UTF-8为了解决我们之前提到的计算机需要能够知道各个字符之间到底在哪里分割,就让二字节编码的第一个字节由 110 开头,表示自己及后面一个字节是一起的,都在表示同一个字符,然后第二个字节由 10 开头, Unicode的二进制码点会被分割为两个部分,填入UTF-8编码的数字里;码点在 2048~65535 范围的字符映射为三字节的二进制数。第一个字节由 1110 开头,表示自己及后面两个字节是一起的,都在表示同一个字符,然后后面两个字节都由 10 开头,Unicode的二进制码点会被分割为三个部分,填入UTF-8编码的数字里;码点在 65536~1114111 范围的字符映射为4字节的二进制数,第一个字节由 11110 开头表示自己及后面三个字节是一起的,然后后面三个字节都由 10 开头,Unicode的二进制码点会被分割成4个部分,填入utf8编码的数字里。
Utf-8第一个好处是兼容 ASCII,Unicod前128个字符正好也是ASCII的字符码点一样,而且UTF-8也会把那些字符映射为一字节长度和ASCII编码相同,这说明把一个ASCII编码的英文文本直接用UTF-8编码进行读取不会有任何问题。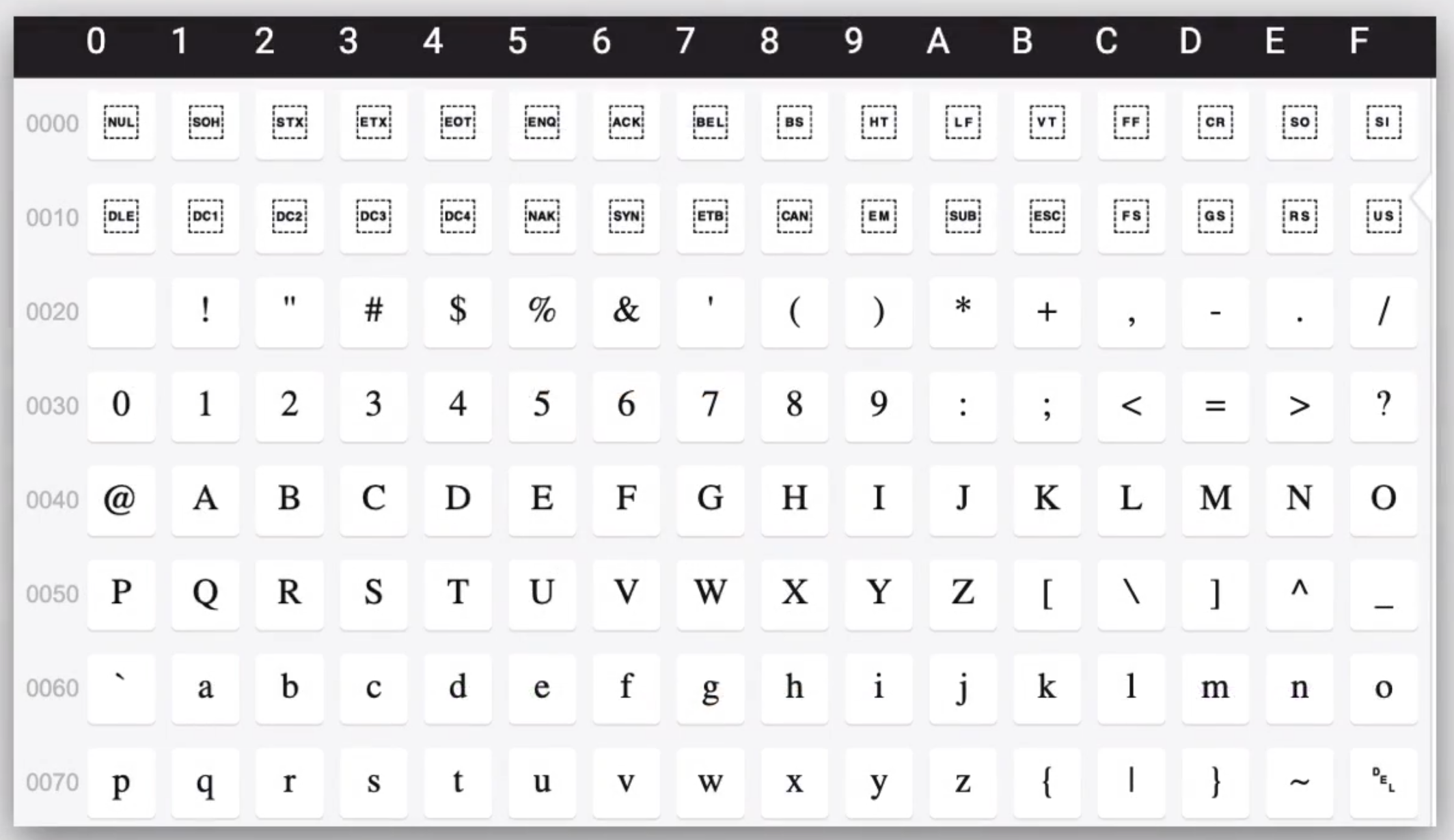

第二个好处是节约空间,Utf-8让 Unicode 里码点小的字符也相应拥有更短的长度,比UTF-32一视同仁的4字节不知道高到哪里去了。通过前缀信息也能让计算机辨别各字符在内存里的总长度,解决分割不明这个问题。在了解编码后,我们应该都意识到选择正确编码的重要性,文本编辑器基本都可以指定编码进行读写,html也会通过head里的meta标签表明该网页的编码,从而让浏览器为用户展示出正确的内容。
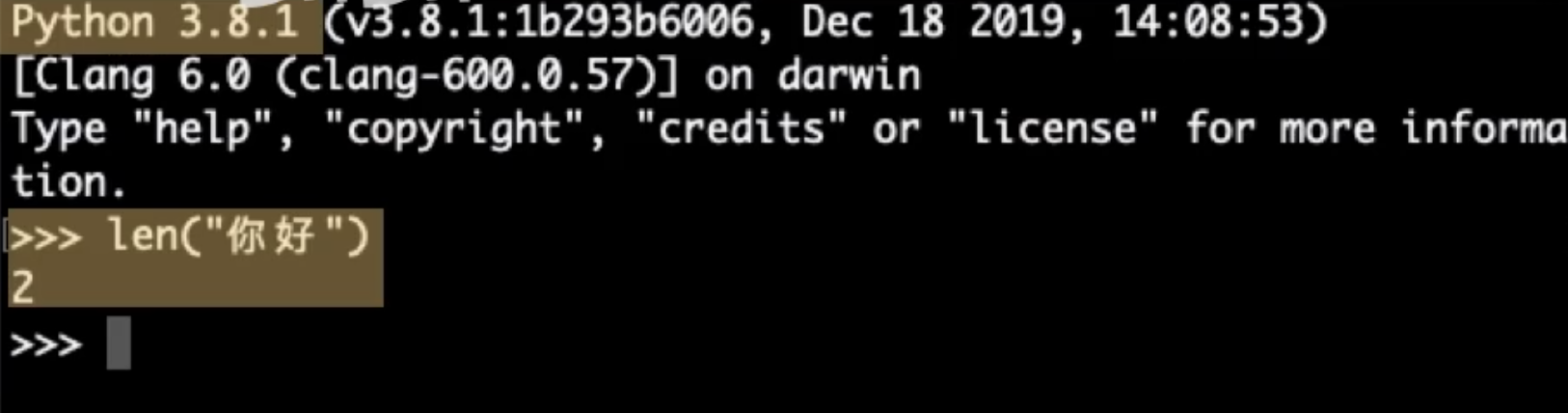
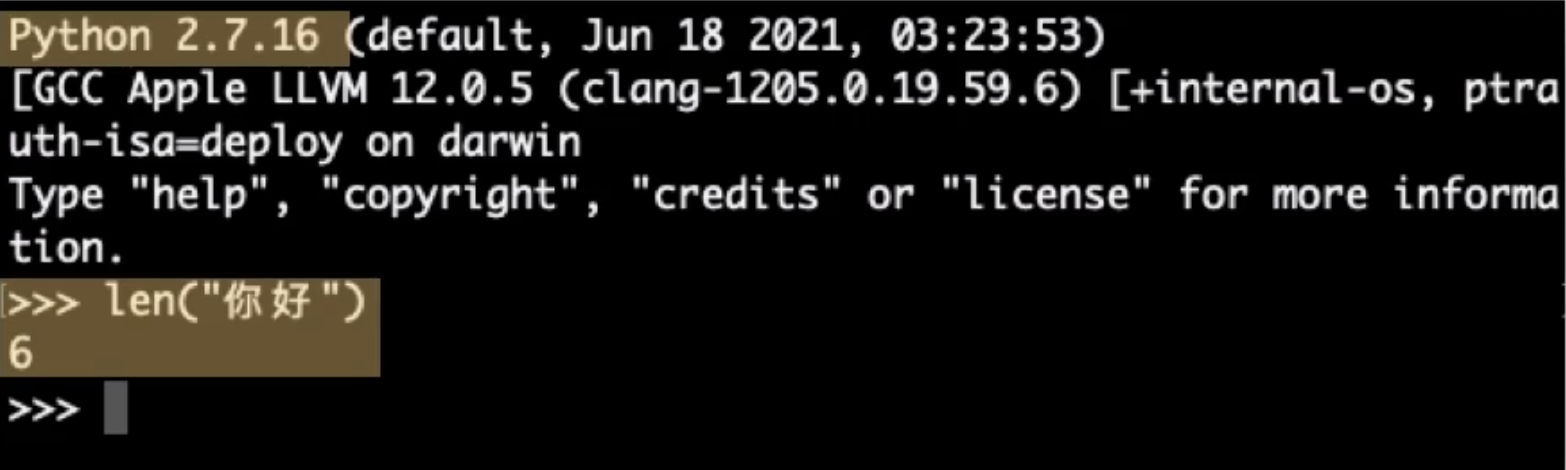
Utf-8如今已经成为最主流的编码,大部分时候他都是默认选择,但有时仍然需要留意,Utf-8是否被支持或兼容或者是否是默认编码。比如python3的默认编码是utf-8,但更老版本的python2,默认编码是ASCII,这导致一个好玩的结果是同样是字符串,你好。用len函数查长度,python3给出的结果是2,python2则是6,这就是因为python2没有把每个汉字字符当成一个整体,只是在数字节数。由于你好占6个字节,python2输出长度为6。
锟斤铐是怎么产生的
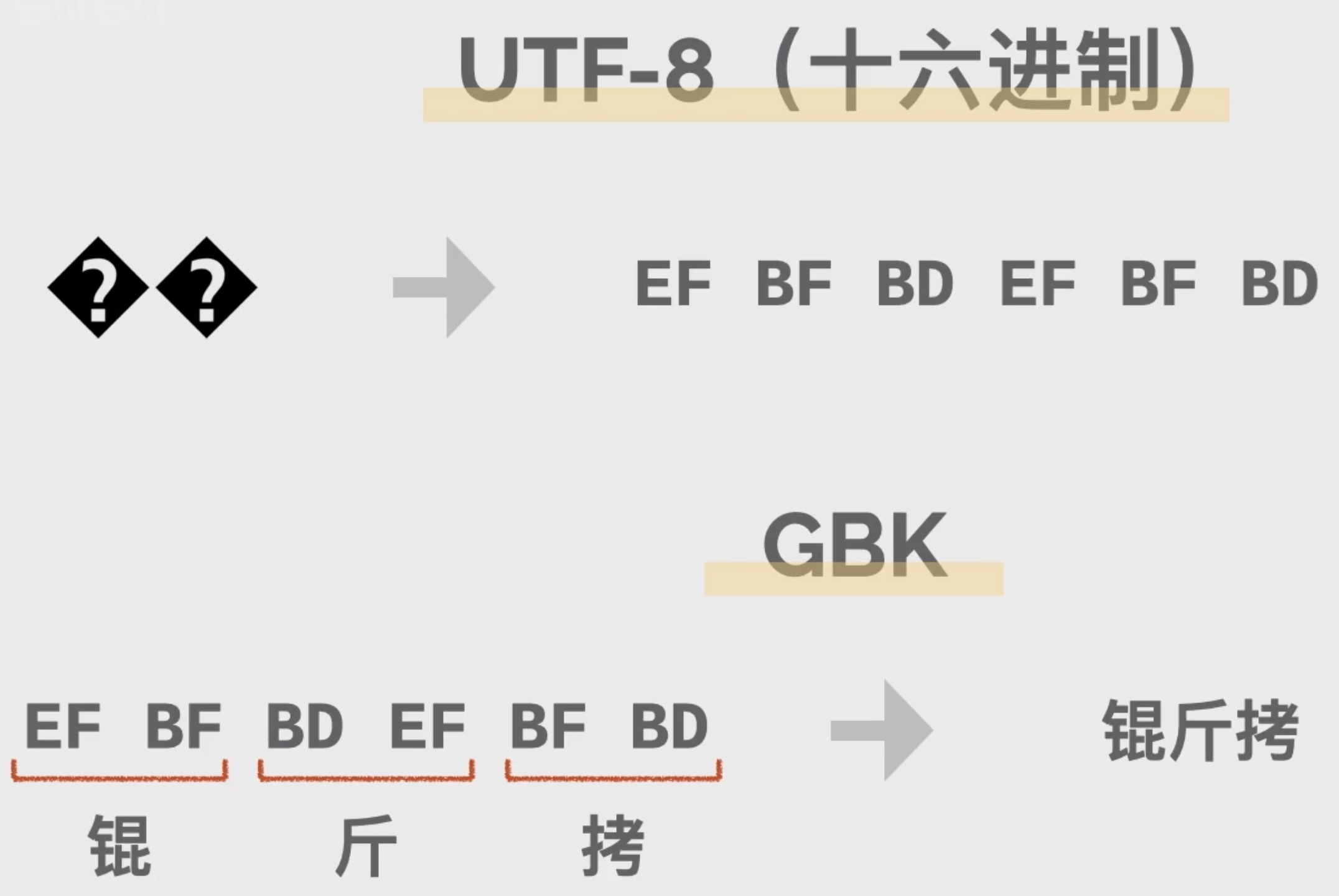
锟斤铐是一个常见的中文乱码,常见到了有了知名度,它一般在utf-8和中文编码比如和gpk 的转换过程中产生。
Unicod字符集有一个特殊的替换符号�,专门用于表示无法识别或展示的字符。
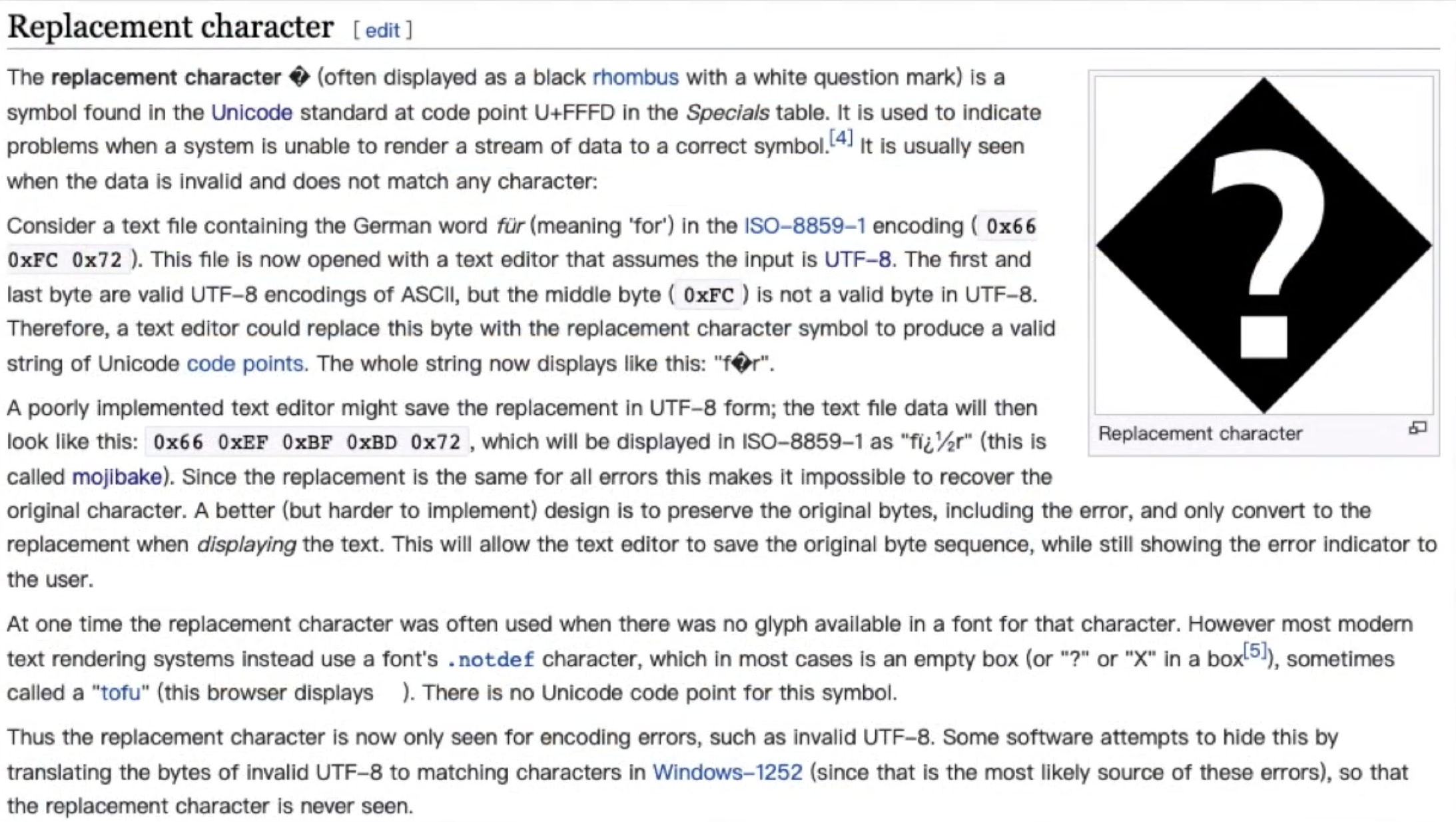
有些大聪明编辑器在编码为utf-8时,会把无法识别或展示的字符自动替换为这个替换符号,用于提示用户。他在utf-8编码后是这个3字节长度的二进制数字,转换成更简洁的16进制,就是 EF BF BD 如果用户在编辑器替换后点了保存,这个特殊符号就会被写入文件内容里,如果有两个替换符号又正好连在一起,内存里就会有 EF BF BD EF BF BD

如果这个时候把文件再用GBK编码读取,或是把文件发送给用GBK编码的朋友,打开后就会看到所有以前是两个替换符号的地方,现在都变成了锟斤铐,因为在GBK中每个汉字用两个字节,储存在计算机里的 EF BF 对应汉字 锟、**BD EF** 对应汉字 斤,**BF BD** 对应汉字 铐,所以乱码神兽锟斤铐是从 utf8 的两个连在一起的替换符号进化来的。