Base64 编解码 前言 在互联网应用中,我们经常需要传输二进制图片、音频等数据,但是普通的文本传输协议如HTTP、SMTP等只能传输ASCII字符,这时就需要将二进制数据转换成可打印字符,以便通过文本方式进行传输。Base64编码就是一种将二进制数据转换为可打印字符的方案。本篇文章就来介绍一下Base64编码的背景、解决的问题和编码规则。
背景 Base64编码最早出现于1977年,由美国国家标准与技术研究院(NIST)提出,当时是作为一种将二进制数据转换为ASCII字符的方法,以便于拨号网络传输。当时的拨号网络设备只支持传输ASCII字符,而无法传输二进制数据。在1980年,Base64编码被加入到了RFC822标准中,以便于邮件传输。之后,Base64编码广泛应用于网络传输、数据存储以及加密等领域。
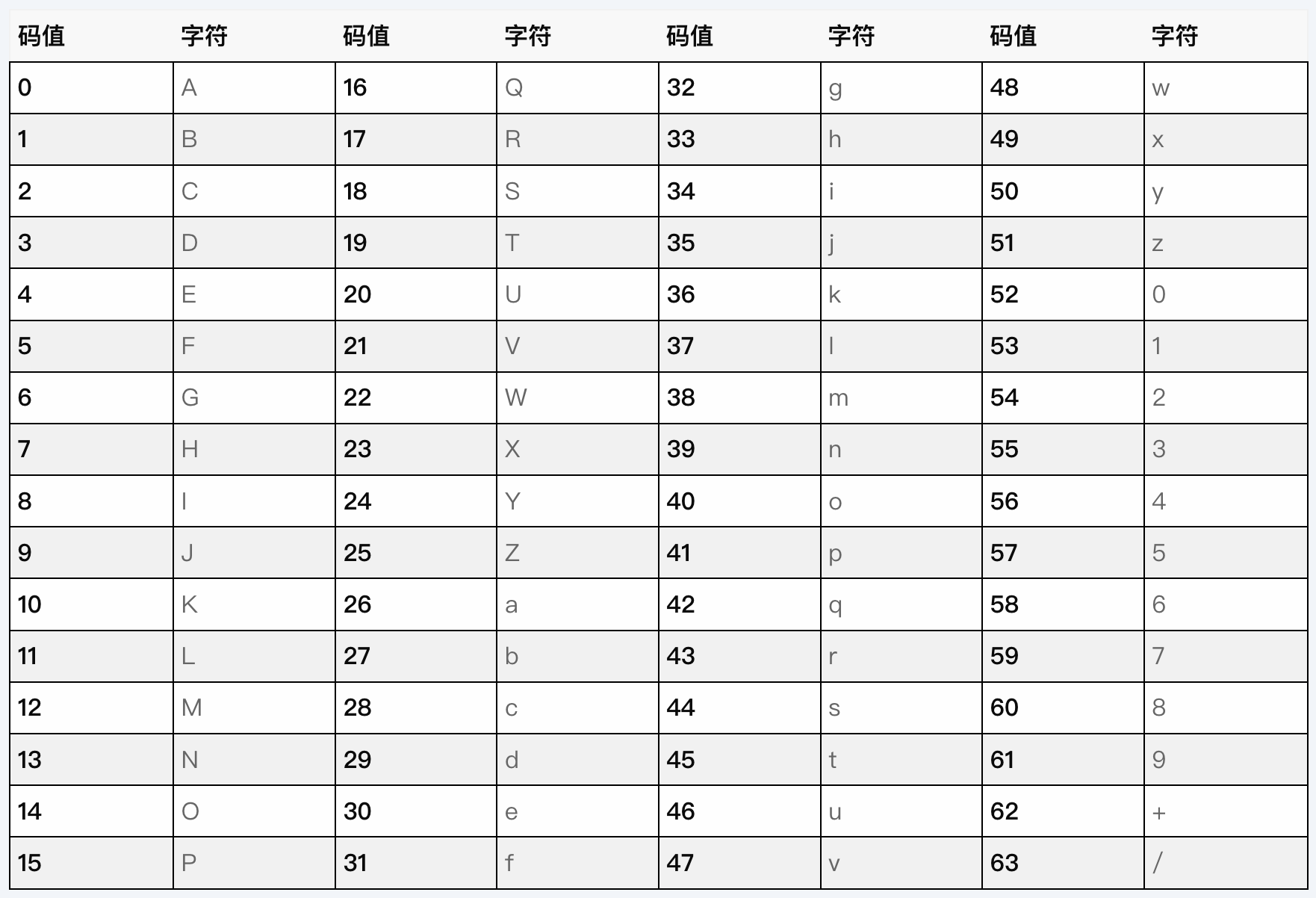
编码规则 Base64编码使用64个字符来表示256个字符集中的数据,它的基本原理是将每3个字节的二进制数据划分成4组,每组6位,但6位不够一个字节,所以再往前补两个0,这样原本的3字节数据,被扩充成了4字节【这就是为什么图片被转成base64之后,体积会增大33%,原本三字节被转成了4字节,体积可不得增大吗 】,然后将这8位的二进制数据转成10进制,然后根据下表进行匹配到对应字符,将这些字符拼接起来,就成了我们看到的base64编码。
【不够三字节】单字节编码 但是 每三个字节作为一组,如果遇到不够3字节的数据呢,例如:
M 它就只有一个字节,根据上面的规则,我们需要获得 M 的二进制数据,怎么做呢
我们先获取 M 的码点
然后将其转为8位的二进制数据
1 'M' .charCodeAt (0 ).toString (2 ).padStart (8 ,'0' )
然后以每6位对其进行分组,我们得到
然后在每组的前面补两个0,得到
这样第一组够8位了,但第二组只有四位,base64规定如果最后一组只有两位,我们处理往前补两个0外,还需往后补4个零,补足8位 然后我们就能得到
然后再将这两组转成10进制
1 ['00010011' , '00010000' ].map (item =>parseInt (item, 2 ))
然后根据上方的 base64 编码表,可得知 【19为T,16为Q】,所以base64对M进行编码为 TQ
但是 base64 要求 3 字节补0扩充为4字节,目前 TQ 只有两字节,所以base64规定 如果不足四字节,往后补=,用来表示填充的字节数
所以填充 = 后,我们就得到了最终的编码内容 TQ==
【不够三字节】双字节编码 如果是两个字节,也就是16位,16位以每6位一组进行分割,每组长度为[6,6,4] ,base64规定,如果最后一组只有4位,除了往前补两个0外,还需往后补两个0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 const str = 'Mn' let i = 0 ;let codePointList = []while (i<str.length ) { codePointList.push (str.charCodeAt (i)) i++ } console .log (codePointList) i = 0 while (i < str.length ) { codePointList[i] = codePointList[i].toString (2 ).padStart (8 ,'0' ) i++ } console .log (codePointList) codePointList = codePointList.join ('' ); codePointList = codePointList.match (/.{1,6}/g ); console .log (codePointList) i = 0 while (i < codePointList.length ) { if (codePointList[i].length === 6 ) { codePointList[i] = `00${codePointList[i]} ` } if (codePointList[i].length === 4 ) { codePointList[i] = `00${codePointList[i]} 00` } if (codePointList[i].length === 2 ) { codePointList[i] = `00${codePointList[i]} 0000` } i++ } console .log (codePointList) const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' let base64 = codePointList.reduce ((prev, curr ) => { prev = prev + keyStr[parseInt (curr, 2 )] return prev }, '' ) const remainder = base64.length % 4 ;const repeatLength = remainder ? 4 - remainder : 0 ;base64 = base64 + `=` .repeat (repeatLength) console .log (base64)
解码–字符串 知道了编码规则后,我们就可以进行解码了
我们先将编码后的base64字符串以4位一组进行划分
1 2 3 4 5 let str = 'TW5yZ2ZzZ3hjeA==' ;const getGroupByStr = (str ) => { return str.match (/.{1,4}/g ); } getGroupByStr (str)
我们获取每组每个字符在base64编码表中的码点,然后将其转为8位的二进制
1 2 3 4 5 6 7 8 9 10 11 12 13 let groups = getGroupByStr (str);const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' groups = groups.map ((item ) => { return item.split ('' ).reduce ((prev, curr ) => { if (curr === '=' ) return prev; return prev + keyStr.indexOf (curr).toString (2 ).padStart (8 , '0' ) }, '' ); }) console .log (groups)
去掉头部添加的两个0,将4字节还原成两字节(针对原始够3字节的二进制);
1 2 3 4 5 6 7 8 9 groups = groups.reduce ((prev, item ) => { const bytes = item.match (/.{1,8}/g ).map (i => return i.slice (2 ) }) if (bytes.length === 3 ) bytes[bytes.length - 1 ] = bytes[bytes.length - 1 ].slice (0 , 4 ); if (bytes.length === 2 ) bytes[bytes.length - 1 ] = bytes[bytes.length - 1 ].slice (0 , 2 ); prev.push (...bytes.join ('' ).match (/.{1,8}/g )) return prev }, [])
将二进制还原成10进制,转成 unicode 字符
1 2 3 groups.reduce ((prev, curr ) => { return prev+String .fromCodePoint (parseInt (curr, 2 )) }, '' )
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 const getByteByBase64 = (str ) => { const getGroupByStr = (str ) => { return str.match (/.{1,4}/g ); } let groups = getGroupByStr (str); const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' groups = groups.map ((item ) => { return item.split ('' ).reduce ((prev, curr ) => { if (curr === '=' ) return prev; return prev + keyStr.indexOf (curr).toString (2 ).padStart (8 , '0' ) }, '' ); }) groups = groups.reduce ((prev, item ) => { const bytes = item.match (/.{1,8}/g ).map (i => return i.slice (2 ) }) if (bytes.length === 3 ) bytes[bytes.length - 1 ] = bytes[bytes.length - 1 ].slice (0 , 4 ); if (bytes.length === 2 ) bytes[bytes.length - 1 ] = bytes[bytes.length - 1 ].slice (0 , 2 ); prev.push (...bytes.join ('' ).match (/.{1,8}/g )) return prev }, []) return groups; } const decode = (str ) => { return groups = getByteByBase64 (str) return groups.reduce ((prev, curr ) => { return prev+String .fromCodePoint (parseInt (curr, 2 )) }, '' ) }
UTF-16编码 js 的字符串编码采用 utf-16 进行编码
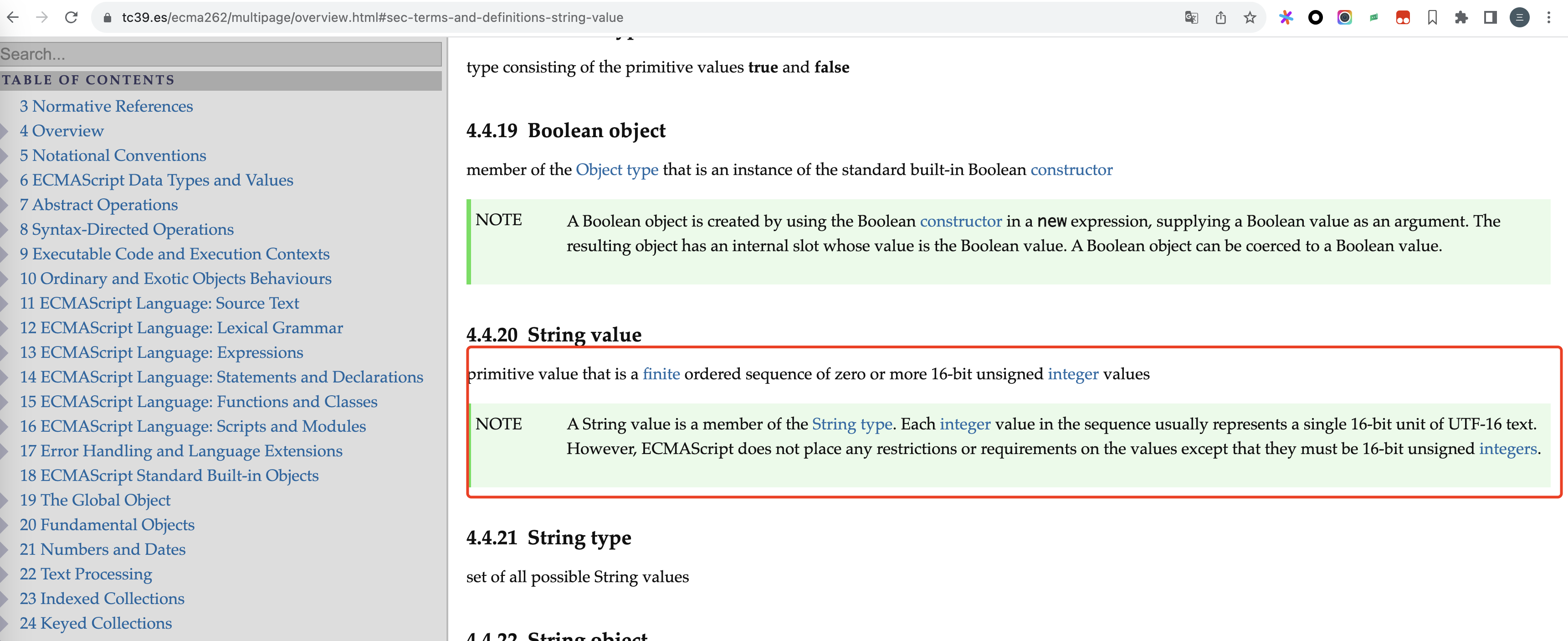
ECMA262对字符串值的定义
UTF-16 所能表示的最大数字为 16个11111111111111111 即65535,也就是说最多可以表示 65515个字符。
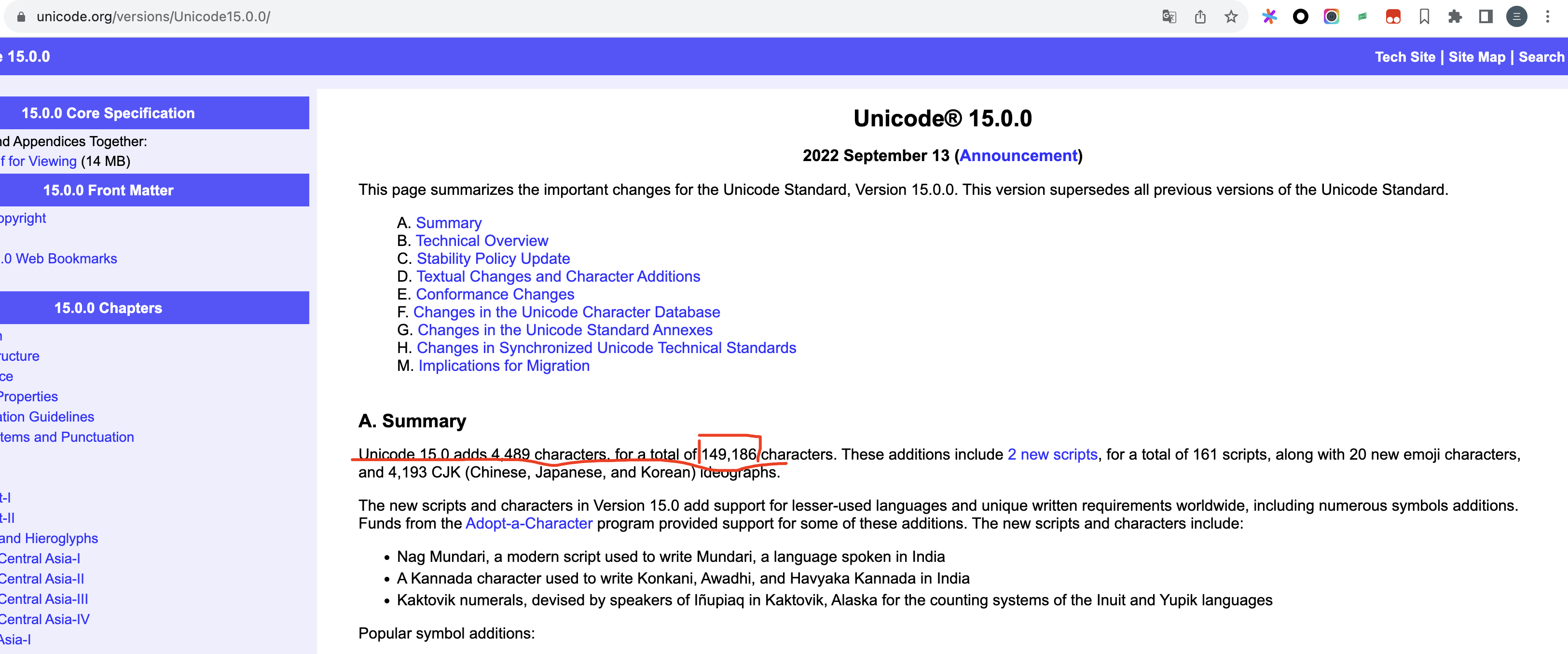
但是unicode字符集目前的可表示的字符数为149186(unicode15.0.0 2022.9.13)
这就导致用两个字节存储一个字符,无法表达全部的 unicode 字符,因此就出现了其他的编码方式,如 utf-8 utf-32
UTF-32 统一使用4个字节存储一个字符,可以表示 4294967295 个字符,但是这就导致本身使用 ASCII 编码,只占一个字节大小,现在采用utf-32要占用四个字节大小,空间占用平白增大了四倍,采用GBK编码的中文,本身只占两个字节,现在也增大了两倍,这就导致最终UTF-32编码应用的并没有那么广泛。
UTF-8 是一种可变长的编码规范,对于不同字符的存储,可以是8比特、16比特、24比特、32比特,最小是8比特,由于变长的特性,最终使得 utf-8 成为现在主流的编码方式。
但是为什么javascript使用的是 utf-16编码方式
历史原因:JavaScript 最初在设计之初就采用了 UTF-16 编码。1995 年发布的 JavaScript 是为了处理网页上的简单脚本交互而设计的,当时的 Web 平台主要使用 Latin-1 编码,而 UTF-16 能够兼容 Latin-1,并且支持更多的字符。
兼容性:JavaScript 的开发者希望保持向后兼容性,以确保现有的 JavaScript 代码和库能够继续运行。如果 JavaScript 在现有的基础上改用 UTF-8 编码,将会破坏现有的字符串处理逻辑,导致兼容性问题。
效率考虑:UTF-16 编码在处理 BMP 中的字符时非常高效,因为每个字符都可以用一个 16 位编码单元表示。这在大多数情况下足够满足需求。而 UTF-8 编码的可变长度特性意味着需要更多的字节来表示字符,这会增加字符串处理的复杂性和内存占用。
但是 UTF-16 也是可变长的编码方式,只是最小存储是16比特,这就使得 utf-16也可以表示目前所有的unicode字符
对于 U+0000(0) 到 U+FFFF(65535) 内的字符统一采用固定长度2字节存储
对于 U+10000(65536) 到 U+10FFFF(1114111) 内的字符统一采用4字节存储
但是如果我们使用定长16比特来表示一个字符,那对于 10010110001111110101010101001010 这样一个二进制数据,我就知道我应该每隔16位将其分割,其中每一个16位表示一个字符,通过解析我们知道这个二进制数据是 阿啊
1 '10010110001111110101010101001010' .match (/.{1,16}/g ).map (item =>String .fromCodePoint (parseInt (item,2 ))).join ('' )
但是对于这样 100101100011111111111100100100011 一个二进制数据,它有33位,我们无法确认应该如何分割,因为我们无法知道多少比特是一个字符。以上这个二进制数据的字符是 阿🤣,其中前16位两个字节是【阿】后17位是【🤣】
也许你会说无法分割那是因为我们是33位,不是一个整数字节,那现在我们让【🤣】占3个字节,然后调整一下顺序变为【🤣阿】,然后二进制为 0000000111111001001000111001011000111111 ,你会发现你还是无法分割,如果以16位进行分割,前两个字节是【🤣】的一部分,但无法完整表示出【🤣】,中间两个字节是【🤣】的最后一部分和【阿】的前一部分,最后一个字节是【阿】的后一部分,那一组都无法完整表示出原字符。
但幸好 ,从1到65535并非每一个数字都映射了一个字符,其中 U+D800(55296) 到 U+DFFF(57343)共 2048 个码位,是永久保留的,不映射到任何 Unicode 字符,它的存在为 UTF-16 变长提供了方便。
U+D800(55296) 到 U+DFFF(57343) 2048个码位又分了两组
其中U+D800(55296) 到 U+DBFF(56319) 表示高位;
U+DC00(56320) 到 U+DFFF(57343) 表示低位;
高位+低位 四个字节形成一个字符,也就是说如果我们以16位为分割点,则每一组16位的数字都在65535内,其中如果这组数字在 U+D800(55296) 到 U+DBFF(56319) 之间,那我们就知道这是一个高位,紧跟在它后一组则是低位,那我们就可以把这两组划分为一个字符。那我们如何使用 【高位】+【低位】来表示一个字符呢?
继续以【🤣】为例,我们可以通过 '🤣'.codePointAt() 得倒它的码位为 129315(U+1F923)
我们用 129315 减去 65536 得倒 63779 ,二进制表示为 1111100100100011
我们向前补0,将其补到20位,得倒 00001111100100100011
将其分为两组 0000111110(62) 0100100011(291)
给第一组加上 U+D800(55296) 形成高位 55296 + 62 = 55358(0xD83E)
给第二组加上 U+DC00(56320) 形成低位 56320 + 291 = 56611(0xDD23)
0xD83E 和 0xDD23 构成一个代理对,用来表示 U+1F923 字符
然后我们继续看【🤣阿】的二进制串,我们现在知道了【🤣】的高位和低位,那我们就把他们都转为二进制,再加上【阿】的二进制,即可得到它们的二进制串 110110000011111011011101001000111001011000111111
对于这个二进制串我们每16位进行一次分割,即可得倒 1101100000111110(55358) 1101110100100011(56611) 1001011000111111(38463)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ['1101100000111110' ,'1101110100100011' ,'1001011000111111' ].reduce ((prev,curr ) => { const num = parseInt (curr, 2 ) if (prev.high ) { const codePoint = parseInt (prev.high + (num - 56320 ).toString (2 ).padStart (10 , 0 ), 2 ) + 65536 ; prev.str = prev.str + String .fromCodePoint (codePoint) prev.high = undefined return prev; } if (num < 55296 || num > 57343 ) { prev.str = prev.str + String .fromCharCode (num) return prev; } prev.high = (num - 55296 ).toString (2 ).padStart (10 , 0 ) return prev }, {str : '' , high : undefined })
关于为什么补位补到20位
0x000000 到 0x00FFFF 的这个区叫基本区,也就是 0 到 65535 的代码点。对于基本区的代码点,最大也就是 0xFFFF, 所以直接 2 个字节就可以表示了,字节内容就是代码点的二进制。
剩余的 0x010000 到 0x10FFFF 统称拓展区。对于拓展区的代码点,至少需要 21 个 bit 才能全部表示出来(比如最大值 0x10FFFF),但拓展区的代码点其实只有 65535 * 16 个,所以理论上 (16+4) bit 就够了(为啥补到20位 )。于是对于拓展区代码点的编码规则就变成了:先把拓展区的代码点直接减去 65536,空间占用就可以压缩到 20 bit 了((0x10FFFE-65536).toString(2).length = 20)。然后 UTF-16 就规定了用 2 个 code unit,即 4 字节来表示拓展区的代码点
多字节 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 let str = 'asd所得税法发的💪🛵⚠️的冲动' let i = 0 ,group = [];while (i < str.length ) { let codeAt = str.charCodeAt (i); codeAt = codeAt.toString (2 ) codeAt = codeAt.padStart (16 ,0 ) group.push (codeAt) i++ } group.reduce ((prev,curr, index ) => { const num = parseInt (curr, 2 ) if (prev.high ) { const codePoint = parseInt (prev.high + (num - 56320 ).toString (2 ).padStart (10 , 0 ), 2 ) + 65536 ; prev.str = prev.str + String .fromCodePoint (codePoint) prev.high = undefined return prev; } if (num < 55296 || num > 57343 ) { prev.str = prev.str + String .fromCharCode (num) return prev; } prev.high = (num - 55296 ).toString (2 ).padStart (10 , 0 ) return prev }, {str : '' , high : undefined })
utf-16 base64编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' let str = 'asd所得税法发的💪🛵⚠️的冲动' let i = 0 ,group = [];while (i < str.length ) { let codeAt = str.charCodeAt (i); codeAt = codeAt.toString (2 ) codeAt = codeAt.padStart (16 ,0 ) group.push (codeAt) i++ } let base64 = group.join ('' ).match (/.{1,24}/g ).map (item =>match (/.{1,6}/g ).map (el => let num if (el.length === 6 ) num = `00${el} ` if (el.length === 4 ) num = `00${el} 00` if (el.length === 2 ) num = `00${el} 0000` return keyStr[parseInt (num,2 )] }).join ('' )).join ('' ) let fillInCount = 4 - (base64.length % 4 )if (fillInCount < 4 ) { base64 = base64 + '=' .repeat (fillInCount) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 const blot64 = (str ) => { const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' ; let i = 0 ,group = []; while (i < str.length ) { let codeAt = str.charCodeAt (i); codeAt = codeAt.toString (2 ) codeAt = codeAt.padStart (16 ,0 ) group.push (codeAt) i++ } let base64 = group.join ('' ).match (/.{1,24}/g ).map (item =>match (/.{1,6}/g ).map (el => let num if (el.length === 6 ) num = `00${el} ` if (el.length === 4 ) num = `00${el} 00` if (el.length === 2 ) num = `00${el} 0000` return keyStr[parseInt (num,2 )] }).join ('' )).join ('' ) let fillInCount = 4 - (base64.length % 4 ) if (fillInCount < 4 ) { base64 = base64 + '=' .repeat (fillInCount) } return base64 }
utf-16 base64解码
去掉base64字符串的补位=
将去掉补位后的字符串每4位进行分割 ['X5d6', 'd9g8', '3AT+', 'D1PR', '9Sag', '/g92', 'hFGy', 'Uqg']
然后查找每个字符的base64编码, 然后将其转为2进制,往前补0至8位 keyStr.indexOf(el).toString(2).padStart(8,0) 得到类似如下数组
1 2 3 4 5 6 7 [ [ "00000000" , "00000110" , "00000100" , "00000000" ] , [ "00011100" , "00110000" , "00000000" , "00110100" ] , [ "00000000" , "00000110" , "00011000" , "00000000" ] , [ "00010111" , "00111001" , "00011101" , "00111010" ] , [ "00010100" , "00101010" , "00100000" ] ]
如果当前组的长度是4就去掉每项开头的两个0;如果当前组的长度是3就去掉每项开头的两个0,和最后一项的最后两个0;如果当前组的长度是2就去掉每项开头的两个0,和最后一项的最后4个0;得倒类似如下数组
1 2 3 4 5 6 7 [ [ "000000" , "000110" , "000100" , "000000" ] , [ "011100" , "110000" , "000000" , "110100" ] , [ "000000" , "000110" , "011000" , "000000" ] , [ "010111" , "111001" , "011101" , "111010" ] , [ "010100" , "101010" , "1000" ] ]
将每组拼成字符串,得倒类似如下数组
1 2 3 4 5 6 7 [ '000000000110000100000000 ', '011100110000000000110100 ', '000000000110011000000000 ', '010111111001011101111010 ', '0101001010101000 ' ]
再次拼成字符串 0000000001100001000000000111001100000000001101000000000001100110000000000101111110010111011110100101001010101000
将拼成的字符串以每16位进行分割,因为我们采用的utf-16编码 .match(/.{1,16}/g)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 const atob64 = (str ) => { const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' ; const group = str.replace (/=/g , '' ).match (/.{1,4}/g ).map (item =>split ('' ).map (el =>indexOf (el).toString (2 ).padStart (8 ,0 ))).map (item => if (item.length === 4 ) { return item.map (el =>slice (2 )).join ('' ) } if (item.length === 3 ) { const newItem = item.map (el =>slice (2 )); newItem[newItem.length - 1 ] = newItem[newItem.length - 1 ].slice (0 , 4 ) return newItem.join ('' ) } if (item.length === 2 ) { const newItem = item.map (el =>slice (2 )); newItem[newItem.length - 1 ] = newItem[newItem.length - 1 ].slice (0 , 2 ) return newItem.join ('' ) } }).join ('' ).match (/.{1,16}/g ) return group.reduce ((prev,curr, index ) => { const num = parseInt (curr, 2 ) if (prev.high ) { const codePoint = parseInt (prev.high + (num - 56320 ).toString (2 ).padStart (10 , 0 ), 2 ) + 65536 ; prev.str = prev.str + String .fromCodePoint (codePoint) prev.high = undefined return prev; } if (num < 55296 || num > 57343 ) { prev.str = prev.str + String .fromCharCode (num) return prev; } prev.high = (num - 55296 ).toString (2 ).padStart (10 , 0 ) return prev }, {str : '' , high : undefined }).str ; }
获取文本的UTF-16编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const getUtf16ByTxt = (txt ) => { let i = 0 , utf16 = '' ; while (i < txt.length ) { let codeAt = txt.charCodeAt (i); codeAt = codeAt.toString (2 ) codeAt = codeAt.padStart (16 ,0 ) utf16+=codeAt i++ } return utf16 }
将UTF16还原为文本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 const getTxtByUtf16 = (binary ) => { const group = binary.match (/.{1,16}/g ); const {codePointList} = group.reduce ((prev,curr, index ) => { const num = parseInt (curr, 2 ) if (prev.high ) { const codePoint = parseInt (prev.high + (num - 56320 ).toString (2 ).padStart (10 , 0 ), 2 ) + 65536 ; prev.codePointList .push (codePoint) prev.high = undefined return prev; } if (num < 55296 || num > 57343 ) { prev.codePointList .push (num) return prev; } prev.high = (num - 55296 ).toString (2 ).padStart (10 , 0 ) return prev }, {codePointList : [], high : undefined }) return String .fromCodePoint (...codePointList) }
UTF-8 编码 UTF-8 编码比 UTF16 编码要简单一点,UTF-8 将 unicode 的码点划分为了四个区域;其中0-127码点的字符,在 utf-8编码中占用1个字节,二进制最高位以0开头;128-2047码点的字符,占用两个字节,第一个字节以110开头,第二个字节以10开头;2048-65535码点的字符占三个字节,第一个字节以1110开头,后面两个字节以10开头;65536-1114111码点的字符占4个字节,第一个字节以11110开头,后面三个字节以10开头
区域 (HEX)
区域 (DEC)
二进制编码(0 或 1 的 bit 已固
字节数
可用 bit 数
区域内最大代码
0x000000 到 0x00007F0 到 127
0xxxxxxx
1
7
7
0x000080 到 0x0007FF128 到 2047
110xxxxx 10xxxxxx
2
11
11
0x000800 到 0x00FFFF2048 到 65535
1110xxxx 10xxxxxx 10xxxxxx
3
16
16
0x010000 到 0x10FFFF65536 到 1114111
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
4
21
21
基于此,对Unicode字符的编码步骤就变为了
查码点,eg: '🤣'.codePointAt() // 129315
查区间,eg: 129315 在第四个区间
第四个区间它应该占21位,转为2进制,补足21位往前补0; eg: '🤣'.codePointAt().toString(2).padStart(21, 0) // 000011111100100100011
将它按 【3,6,6,6】位进行分割,再分别往前补【11110,10,10,10】
获取文本的utf-8编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 const getUtf8ByTxt = (txt ) => { let i = 0 , utf8 = '' ; const strArr = Array .from (txt); const getGroup = (codePoint ) => { if (codePoint < 128 ) return [codePoint.toString (2 ).padStart (8 ,0 )]; if (codePoint < 2048 ) return codePoint.toString (2 ).padStart (11 ,0 ).match (/(.{5})(.{6})/ ).slice (1 ); if (codePoint < 65536 ) return codePoint.toString (2 ).padStart (16 ,0 ).match (/(.{4})(.{6})(.{6})/ ).slice (1 ); if (codePoint < 1114112 ) return codePoint.toString (2 ).padStart (21 ,0 ).match (/(.{3})(.{6})(.{6})(.{6})/ ).slice (1 ); } while (i < strArr.length ) { const codePoint = strArr[i].codePointAt (); const group = getGroup (codePoint); if (group.length === 1 ) { utf8+=group[0 ] } if (group.length === 2 ) { utf8+=(`110${group[0 ]} 10${group[1 ]} ` ) } if (group.length === 3 ) { utf8+=(`1110${group[0 ]} 10${group[1 ]} 10${group[2 ]} ` ) } if (group.length === 4 ) { utf8+=(`11110${group[0 ]} 10${group[1 ]} 10${group[2 ]} 10${group[3 ]} ` ) } i++ } return utf8 }
将UTF8还原为文本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 const getTxtByUtf8 = (binary ) => { const group = binary.match (/.{1,8}/g ) let i = 0 ; txt = '' ; while (i < group.length ) { if (group[i].startsWith ('11110' )) { txt += String .fromCodePoint (parseInt (`${group[i].slice(5 )} ${group[i + 1 ].slice(2 )} ${group[i + 2 ].slice(2 )} ${group[i + 3 ].slice(2 )} ` , 2 )) i = i + 4 ; continue ; } if (group[i].startsWith ('1110' )) { txt += String .fromCodePoint (parseInt (`${group[i].slice(4 )} ${group[i + 1 ].slice(2 )} ${group[i + 2 ].slice(2 )} ` , 2 )) i = i + 3 continue ; } if (group[i].startsWith ('110' )) { txt += String .fromCodePoint (parseInt (`${group[i].slice(3 )} ${group[i + 1 ].slice(2 )} ` , 2 )) i = i + 2 continue ; } txt += String .fromCodePoint (parseInt (group[i], 2 )) i++ } return txt }
二进制base64编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const toBase64ByBinary = (binary ) => { const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' ; const group = binary.match (/.{1,24}/g ) let base64 = group.map (item =>match (/.{1,6}/g ).map (el => let num if (el.length === 6 ) num = `00${el} ` if (el.length === 4 ) num = `00${el} 00` if (el.length === 2 ) num = `00${el} 0000` return keyStr[parseInt (num,2 )] }).join ('' )).join ('' ) let fillInCount = 4 - (base64.length % 4 ) if (fillInCount < 4 ) { base64 = base64 + '=' .repeat (fillInCount) } return base64 }
base64解码为二进制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 const toBinaryByBase64 = (base64 ) => { const keyStr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' ; const group = base64.replace (/=/g , '' ).match (/.{1,4}/g ) return group.map (item => return item.split ('' ).map (el =>indexOf (el).toString (2 ).padStart (8 ,0 )) }).map (item => if (item.length === 4 ) { return item.map (el =>slice (2 )).join ('' ) } if (item.length === 3 ) { const newItem = item.map (el =>slice (2 )); newItem[newItem.length - 1 ] = newItem[newItem.length - 1 ].slice (0 , 4 ) return newItem.join ('' ) } if (item.length === 2 ) { const newItem = item.map (el =>slice (2 )); newItem[newItem.length - 1 ] = newItem[newItem.length - 1 ].slice (0 , 2 ) return newItem.join ('' ) } }).join ('' ) }
解码图片 1 2 3 4 5 6 7 8 9 10 11 12 let str = '/* 图片 base64 */' ;const bytes = getByteByBase64 (str);const byteArray = new Uint8Array (bytes.map (item =>parseInt (item, 2 )));const blob = new Blob ([byteArray], { type : 'application/octet-stream' });const link = document .createElement ('a' );link.href = URL .createObjectURL (blob); link.download = 'example.png' ; link.click ()